Within AI Takeoff
Do today's self improving systems prove anything?
Narrow systems already improve parts of their own performance, but the gap between that and open-ended self-improvement is large.
On this page
- What self play and AutoML actually show
- Why narrow optimisation is not an intelligence explosion
- How this evidence should update p(doom) debates
Page outline Jump by section
Introduction
When people discuss recursive AI improvement and the possibility of an intelligence explosion, they often point to systems such as AlphaGo Zero, AlphaZero, neural architecture search (NAS), and AutoML as evidence that AI can already improve itself. There is some truth to this. Modern AI systems can generate training data through self-play, discover better strategies than human experts, and automate parts of the machine-learning development process. These are genuine examples of machines contributing to their own improvement. [Google DeepMind]deepmind.googlealphago zero starting from scratchGoogle DeepMindAlphaGo Zero: Starting from scratch18 Oct 2017 — After just three days of self-play training, AlphaGo Zero emphatically de…
 However, the leap from these achievements to the kind of open-ended recursive self-improvement that appears in many AI doom arguments is large. Self-play and AutoML provide evidence that some improvement loops can be automated, but they do not demonstrate a system that autonomously redesigns itself, sets its own objectives, overcomes bottlenecks across many domains, and repeatedly drives its own capabilities upward without human direction. For that reason, most analysts treat them as weak rather than decisive evidence for recursive improvement. [agathon.ai]agathon.aiSelf-improving systems: the AI architecture pattern…Automated machine learning (AutoML) platforms provide another approximation of sel… [LinkedIn]linkedin.comLinkedInWhy AutoML Isn't Auto Yet: The Real Problems of Self-…Most so-called “self-improving” systems still rely on human-defined sear…
However, the leap from these achievements to the kind of open-ended recursive self-improvement that appears in many AI doom arguments is large. Self-play and AutoML provide evidence that some improvement loops can be automated, but they do not demonstrate a system that autonomously redesigns itself, sets its own objectives, overcomes bottlenecks across many domains, and repeatedly drives its own capabilities upward without human direction. For that reason, most analysts treat them as weak rather than decisive evidence for recursive improvement. [agathon.ai]agathon.aiSelf-improving systems: the AI architecture pattern…Automated machine learning (AutoML) platforms provide another approximation of sel… [LinkedIn]linkedin.comLinkedInWhy AutoML Isn't Auto Yet: The Real Problems of Self-…Most so-called “self-improving” systems still rely on human-defined sear…
What self-play and AutoML actually show
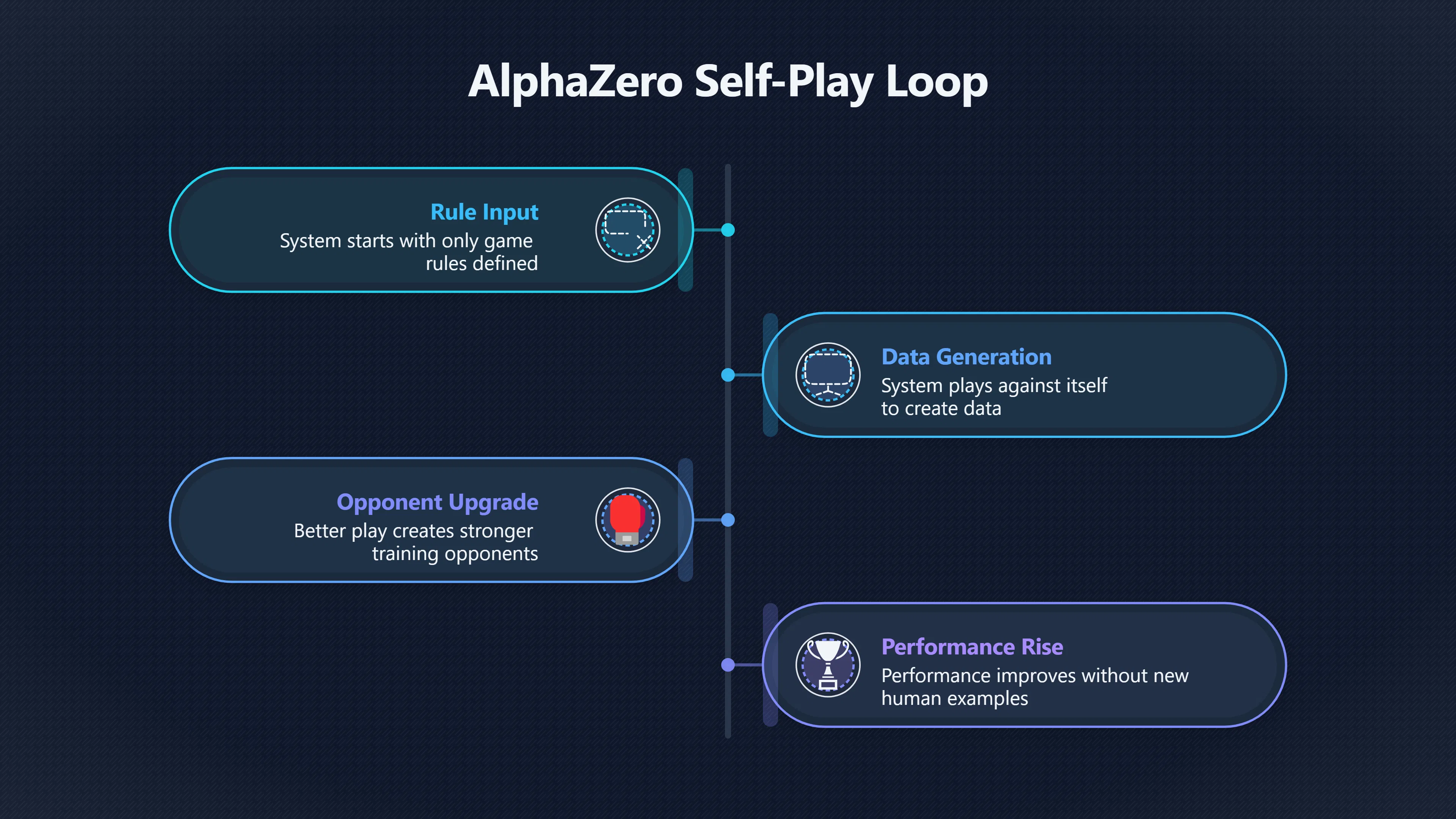
The strongest evidence comes from self-play systems. In games such as Go, chess, and shogi, DeepMind’s AlphaGo Zero and AlphaZero began with only the rules of the game and improved by repeatedly playing against themselves. AlphaGo Zero rapidly surpassed earlier versions of AlphaGo and eventually exceeded the performance of leading human players. [Google DeepMind]deepmind.googlealphago zero starting from scratchGoogle DeepMindAlphaGo Zero: Starting from scratch18 Oct 2017 — After just three days of self-play training, AlphaGo Zero emphatically de…
For supporters of recursive-improvement concerns, this is important because it demonstrates a positive feedback loop:
- The system generates its own training data.
- Better play creates stronger opponents.
- Stronger opponents create better training opportunities.
- Performance continues to improve without new human examples.
That looks superficially similar to the recursive cycles imagined in intelligence-explosion scenarios. [Google DeepMind]deepmind.googlealphago zero starting from scratchGoogle DeepMindAlphaGo Zero: Starting from scratch18 Oct 2017 — After just three days of self-play training, AlphaGo Zero emphatically de…
AutoML and neural architecture search provide a second example. These methods automate tasks that were once performed by human machine-learning engineers, including hyperparameter tuning, model selection, feature engineering, and sometimes the design of neural-network architectures. Researchers often describe NAS as automating part of the model-design process itself. [ML4AAD]ml4aad.orgML4AADNeural Architecture Search: A Surveyby T Elsken · Cited by 4593 — Neural Architecture Search (NAS), the process of automating archi… [Journal of Machine Learning Research]jmlr.orgJournal of Machine Learning ResearchNeural Architecture Search: A Surveyby T Elsken · 2019 · Cited by 4601 — Neural Architecture Search (…
From a recursive-improvement perspective, the interesting observation is that AI can increasingly help build better AI. The boundary between “user” and “tool” becomes less clear when machine-learning systems are selecting architectures, searching design spaces, or generating code that improves other systems. [Springer]link.springer.comSpringerAutomated machine learning: past, present and futureby M Baratchi · 2024 · Cited by 188 — Automated machine learning (AutoML) is…
These developments therefore provide real evidence that at least some components of AI development can be automated.
Why narrow optimisation is not an intelligence explosion
The key limitation is that self-play and AutoML operate inside carefully defined environments.
AlphaZero does not decide what game to learn, invent new objectives, acquire more computing resources, redesign its own learning algorithm, or choose entirely new research directions. Humans specify the rules, reward function, training process, hardware, and evaluation criteria. The system optimises within those constraints. [Google DeepMind]deepmind.googlealphago zero starting from scratchGoogle DeepMindAlphaGo Zero: Starting from scratch18 Oct 2017 — After just three days of self-play training, AlphaGo Zero emphatically de…
Similarly, AutoML systems search within spaces defined by human designers. Researchers choose the objective function, determine which architectures are eligible for consideration, allocate compute budgets, and decide how success is measured. AutoML automates optimisation, but it generally does not automate the creation of the optimisation problem itself. [ScienceDirect]sciencedirect.comScienceDirectAutoML: A systematic review on automated machine…by I Salehin · 2024 · Cited by 315 — AutoML (Automated Machine Learning)… [springer]link.springer.comSpringerAutomated machine learning: past, present and futureby M Baratchi · 2024 · Cited by 188 — Automated machine learning (AutoML) is… This distinction matters because recursive self-improvement arguments typically require something stronger:
- The ability to identify and remove a wide range of bottlenecks.
- The ability to improve the process of improvement itself.
- The ability to transfer gains across many domains.
- Relative independence from human supervision.
Current examples show optimisation inside a box. Intelligence-explosion arguments require a system that can repeatedly expand or redesign the box. [agathon.ai]agathon.aiSelf-improving systems: the AI architecture pattern…Automated machine learning (AutoML) platforms provide another approximation of sel… ResearchGate A useful analogy is that a racing car can become faster by driving laps on a track and refining its performance. That demonstrates optimisati [researchgate.net]researchgate.netPDF) Recursive Self-Improvement in AI SystemsFeb 21, 2026 — This paper examines recursive self-improvement (RSI) mechanisms in artificia… on. It does not demonstrate the ability to redesign its engine, build a factory, invent new materials, and create an entirely new generation of vehicles without external help.

The evidence cuts both ways
Self-play systems are often cited as evidence that capability gains can be unexpectedly large. AlphaGo Zero’s rapid progress surprised many observers and showed that human-generated training data was not always necessary for superhuman performance. [Google DeepMind]deepmind.googlealphago zero starting from scratchGoogle DeepMindAlphaGo Zero: Starting from scratch18 Oct 2017 — After just three days of self-play training, AlphaGo Zero emphatically de…
From the perspective of AI doom arguments, this suggests caution. It is dangerous to assume that human expertise is always required for further progress. A sufficiently rich feedback loop can sometimes produce abilities that were not explicitly programmed by developers. [Google DeepMind]deepmind.googlealphago zero starting from scratchGoogle DeepMindAlphaGo Zero: Starting from scratch18 Oct 2017 — After just three days of self-play training, AlphaGo Zero emphatically de…
At the same time, self-play also reveals important limits.
AlphaZero’s success occurred in environments with clear rules, rapid feedback, abundant simulated experience, and objective measures of success. The real world is much messier. Many economically and strategically important tasks involve uncertainty, incomplete information, changing objectives, and ambiguous feedback. Evidence from later analyses has also highlighted blind spots and limitations in AlphaZero-style systems despite their impressive performance. [OpenReview]openreview.netOpen Review Limitations in the Planning Ability of Alpha ZeroAlphaZero's self-play training regime: it excels at winning games but falls short in tasks requiring.Read more…
Likewise, decades of AutoML research have produced valuable tools, but not autonomous AI researchers capable of independently driving machine-learning progress. The field has automated many technical decisions without eliminating the need for human problem formulation, data collection, evaluation design, deployment decisions, and broader scientific judgement. [Springer]link.springer.comSpringerAutomated machine learning: past, present and futureby M Baratchi · 2024 · Cited by 188 — Automated machine learning (AutoML) is…
For sceptics of intelligence-explosion scenarios, this history is evidence that automating one layer of optimisation often reveals new bottlenecks elsewhere.
How this evidence should update p(doom) debates
For readers encountering p(doom) discussions, self-play and AutoML are best understood as modest evidence rather than proof.
They should increase confidence in a limited claim: machines can participate in processes that improve machine capabilities. The idea is no longer purely theoretical. Systems already generate useful training data, discover novel strategies, and automate portions of AI development. [Google DeepMind]deepmind.googlealphago zero starting from scratchGoogle DeepMindAlphaGo Zero: Starting from scratch18 Oct 2017 — After just three days of self-play training, AlphaGo Zero emphatically de… [2ML4AAD]ml4aad.orgML4AADNeural Architecture Search: A Surveyby T Elsken · Cited by 4593 — Neural Architecture Search (NAS), the process of automating archi…
However, they provide much weaker evidence for stronger claims:
- That AI systems can autonomously conduct frontier research.
- That they can repeatedly redesign themselves across multiple capability domains.
- That improvements will accelerate without encountering major bottlenecks.
- That an intelligence explosion is likely or imminent.
Those claims require additional assumptions that are not established by self-play or AutoML alone. [agathon.ai]agathon.aiSelf-improving systems: the AI architecture pattern…Automated machine learning (AutoML) platforms provide another approximation of sel… [LinkedIn As a result]linkedin.comLinkedInWhy AutoML Isn't Auto Yet: The Real Problems of Self-…Most so-called “self-improving” systems still rely on human-defined sear…, different participants in the AI-risk debate interpret the same evidence differently. Doom-oriented analysts often view self-play and AutoML as early examples of a broader pattern: once improvement loops become partially automated, future systems may automate increasingly important parts of AI research itself. Sceptics generally agree that automation is increasing but argue that current examples remain narrow, highly constrained, and far from demonstrating open-ended recursive self-imvement. Reddit [The Algorithmic Bridge]thealgorithmicbridge.comThe Algorithmic BridgeHow Google Created an AI That Improves Itself16 May 2025 — Recursive self-improvement: This, together with the evol… [ACM-VIT]blog.acmvit.inself improving aiACM-VIT BlogsWhen machines learn to learn11 Jun 2025 — The age of self-improving AI is no longer confined to games. DeepMind has already…
The most defensible conclusion is that today’s systems show the possibility of automated improvement loops, not the inevitability of an intelligence explosion. They move the discussion beyond pure speculation, but they leave the central question unresolved: whether narrow optimisation mechanisms can eventually grow into the kind of broad, self-sustaining recursive improvement that would make loss-of-control scenarios substantially more likely. [Google DeepMind]deepmind.googlealphago zero starting from scratchGoogle DeepMindAlphaGo Zero: Starting from scratch18 Oct 2017 — After just three days of self-play training, AlphaGo Zero emphatically de… [2agathon.ai]agathon.aiSelf-improving systems: the AI architecture pattern…Automated machine learning (AutoML) platforms provide another approximation of sel…

Amazon book picks
Further Reading
Books and field guides related to Do today's self improving systems prove anything?. Use these as the next step if you want deeper reading beyond the article.
Superintelligence
Useful contrast between current systems and recursive self-improvement.
Artificial Intelligence
Rating: 4.5/5 from 10 Google Books ratings
Provides technical grounding for self-play, AutoML and AI capabilities.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.








Endnotes
-
Source: deepmind.google
Title: alphago zero starting from scratch
Link: https://deepmind.google/blog/alphago-zero-starting-from-scratch/Source snippet
Google DeepMindAlphaGo Zero: Starting from scratch18 Oct 2017 — After just three days of self-play training, AlphaGo Zero emphatically de...
-
Source: ml4aad.org
Link: https://www.ml4aad.org/wp-content/uploads/2018/07/automl_book_draft_neural_architecture_search.pdfSource snippet
ML4AADNeural Architecture Search: A Surveyby T Elsken · Cited by 4593 — Neural Architecture Search (NAS), the process of automating archi...
-
Source: agathon.ai
Link: https://agathon.ai/insights/self-improving-systems-the-ai-architecture-pattern-everyone-talks-about-nobody-buildsSource snippet
Self-improving systems: the AI architecture pattern...Automated machine learning (AutoML) platforms provide another approximation of sel...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/why-automl-isnt-auto-yet-real-problems-self-improving-kotipalli-zclhcSource snippet
LinkedInWhy AutoML Isn't Auto Yet: The Real Problems of Self-...Most so-called “self-improving” systems still rely on human-defined sear...
-
Source: sciencedirect.com
Link: https://www.sciencedirect.com/science/article/pii/S2949715923000604Source snippet
ScienceDirectAutoML: A systematic review on automated machine...by I Salehin · 2024 · Cited by 315 — AutoML (Automated Machine Learning)...
-
Source: link.springer.com
Link: https://link.springer.com/article/10.1007/s10462-024-10726-1Source snippet
SpringerAutomated machine learning: past, present and futureby M Baratchi · 2024 · Cited by 188 — Automated machine learning (AutoML) is...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/400969455_Recursive_Self-Improvement_in_AI_Systems_Mechanisms_Implications_and_Governance_ChallengesSource snippet
(PDF) Recursive Self-Improvement in AI SystemsFeb 21, 2026 — This paper examines recursive self-improvement (RSI) mechanisms in artificia...
-
Source: openreview.net
Title: Open Review Limitations in the Planning Ability of Alpha Zero
Link: https://openreview.net/pdf?id=ZAbYb4jDJtSource snippet
AlphaZero's self-play training regime: it excels at winning games but falls short in tasks requiring.Read more...
-
Source: reddit.com
Link: [https://www.reddit.com/r/artificialSource snippet
we create, it is probably not as impressive as it sounds, and it is...Read more...
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/401285309_Pattern_Recognition_and_Selective_Search_Comparison_between_AlphaZero_and_Human_ExpertiseSource snippet
Comparison between AlphaZero and Human Expertise4 Mar 2026 — PDF | Research on expertise has identified pattern recognition and selective...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/recursive-intelligence-systems-improving-own-learning-andre-w97leSource snippet
Recursive Intelligence: Systems Improving Their Own...AlphaGo Zero achieved superhuman performance in just 40 days of self-play training...
-
Source: reddit.com
Link: https://www.reddit.com/r/science/comments/a3r8l5/deepminds_alphazero_algorithm_taught_itself_to/Source snippet
DeepMind's AlphaZero algorithm taught itself to play Go...DeepMind's AlphaZero algorithm taught itself to play Go, chess, and shogi with...
-
Source: automl.org
Title: Auto ML Book Chapter3
Link: https://www.automl.org/wp-content/uploads/2019/05/AutoML_Book_Chapter3.pdfSource snippet
Architecture Search (NAS), the process of automating architecture engineering, is thus a logical next step in automating machine learning...
-
Source: jmlr.org
Link: https://www.jmlr.org/papers/volume20/18-598/18-598.pdfSource snippet
Journal of Machine Learning ResearchNeural Architecture Search: A Surveyby T Elsken · 2019 · Cited by 4601 — Neural Architecture Search (...
-
Source: thealgorithmicbridge.com
Link: https://www.thealgorithmicbridge.com/p/how-google-created-an-ai-that-improvesSource snippet
The Algorithmic BridgeHow Google Created an AI That Improves Itself16 May 2025 — Recursive self-improvement: This, together with the evol...
Published: May 2025
-
Source: blog.acmvit.in
Title: self improving ai
Link: https://blog.acmvit.in/self-improving-aiSource snippet
ACM-VIT BlogsWhen machines learn to learn11 Jun 2025 — The age of self-improving AI is no longer confined to games. DeepMind has already...
Additional References
-
Source: interestingengineering.substack.com
Link: https://interestingengineering.substack.com/p/deepminds-alphago-to-alphaevolveSource snippet
Interesting EngineeringDeepMind's AlphaGo to AlphaEvolve: The Thinking Game...AlphaZero generalized the self-play reinforcement learning...
-
Source: ovhcloud.com
Link: https://www.ovhcloud.com/en/learn/what-is-automated-machine-learning/Source snippet
What is automated machine learning (AutoML)?Discover what AutoML is: an approach that automates model building, making machine learning f...
-
Source: towardsai.net
Link: https://towardsai.net/p/l/automl-nas-and-hyperparameter-tuning-navigating-the-landscape-of-machine-learning-automationSource snippet
“AutoML, NAS and Hyperparameter Tuning: Navigating the...17 Jul 2023 — AutoML, neural architecture search (NAS), and hyperparameter tuni...
-
Source: x.com
Link: https://x.com/robbensinger/status/2035195169272995891 -
Source: youtube.com
Link: https://www.youtube.com/watch?v=Ap9ngcDDAp4Source snippet
Architects of Intelligence: From AutoML to Recursive Self...Let's dive into this fascinating and kind of mind-bending world where AI beg...
-
Source: dwarkesh.com
Link: https://www.dwarkesh.com/p/demis-hassabisSource snippet
We discuss: Why scaling is an artform. Adding search, planning, & AlphaZero type training...Read more...
-
Source: pmc.ncbi.nlm.nih.gov
Title: PMCAcquisition of chess knowledge in Alpha Zero
Link: https://pmc.ncbi.nlm.nih.gov/articles/PMC9704706/Source snippet
PMCAcquisition of chess knowledge in AlphaZero - PMC - NIHby T McGrath · 2022 · Cited by 276 — We analyze the knowledge acquired by Alpha...
-
Source: medium.com
Link: https://medium.com/%40AngelinaRule/automl-a-systematic-review-on-automated-machine-learning-designing-machine-learning-systems-and-2cfef18642a2Source snippet
AutoML: A systematic review on automated machine...AutoKeras utilizes neural architecture search to optimize code writing, machine learn...
-
Source: marsggbo.github.io
Link: https://marsggbo.github.io/automl_a_survey_of_state_of_the_art/papers.htmlSource snippet
AutoMLReinforcement Learning for Neural Architecture Search: A Review, Image and Vision Computing; A Survey on Neural Architecture Searc...
-
Source: bizrescuepro.com
Title: self improving ai intelligence explosion alphazero
Link: https://bizrescuepro.com/self-improving-ai-intelligence-explosion-alphazero/Source snippet
Demis Hassabis on the "Intelligence Explosion", Self-...27 May 2025 — This article explores the fascinating interplay between self-play...
Published: May 2025
Topic Tree