Within Release Races
Can lab safety promises survive launch races?
Voluntary deployment rules may slow unsafe releases, but their strength depends on whether labs uphold them when competition intensifies.
On this page
- How responsible scaling policies are meant to work
- Where voluntary commitments can bend under pressure
- What stronger release gates would need
Page outline Jump by section
Introduction
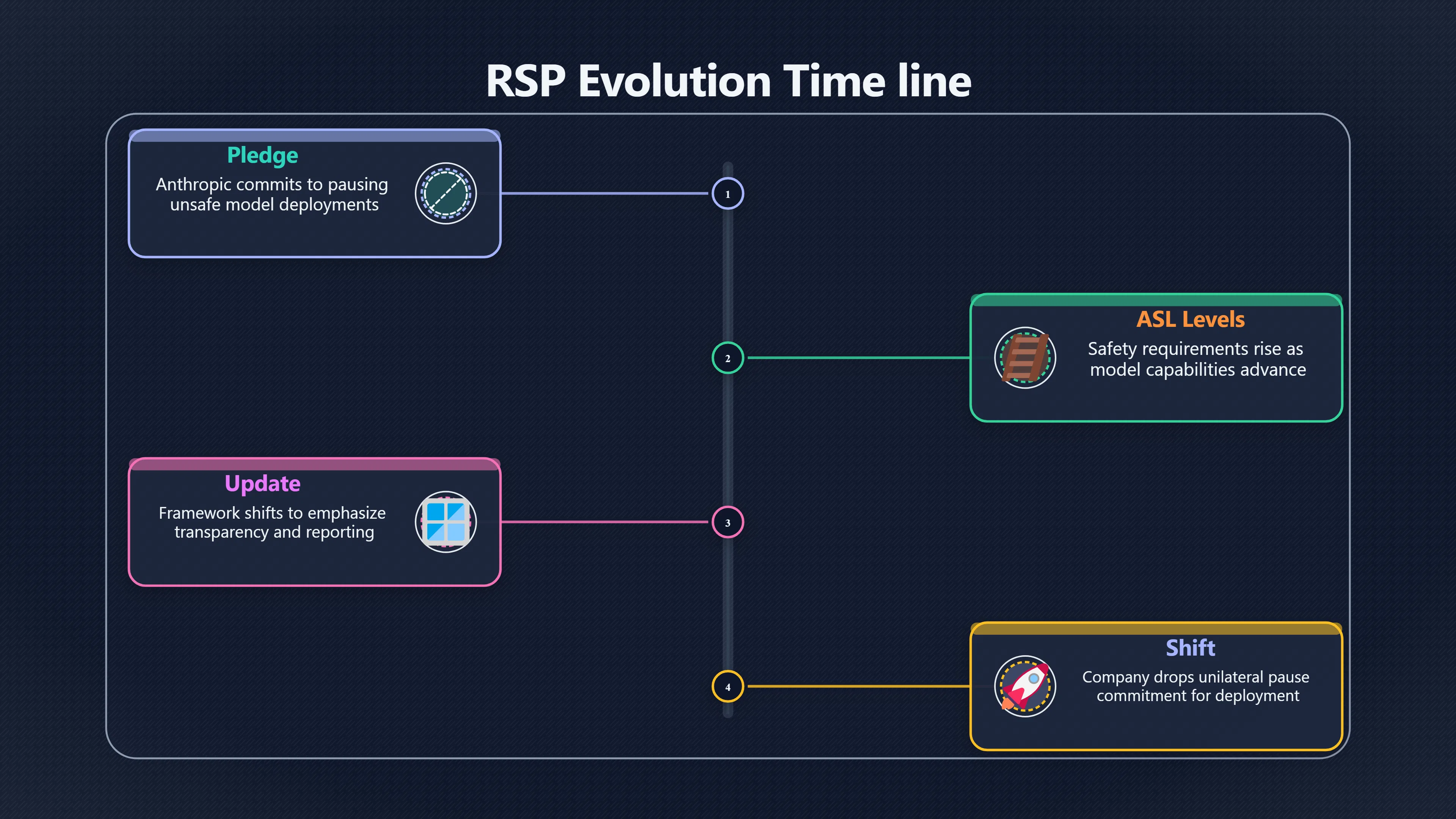
Can lab safety promises survive AI launch races? The answer is: possibly, but only under limited conditions. Responsible scaling policies (RSPs) and related frontier safety frameworks were created partly to address a central AI doom concern: that competition between leading labs could push increasingly powerful systems into deployment before their risks are properly understood. These policies attempt to pre-commit organisations to specific safety actions when models reach defined capability thresholds. Instead of asking executives to make difficult judgement calls under competitive pressure, the idea is to establish rules in advance. [Anthropic]anthropic.comAnthropicAnthropic's Responsible Scaling PolicyIn our Responsible Scaling Policy, reaching certain Capability Thresholds requires us to u…
 Whether this works in practice remains disputed. Supporters argue that predefined thresholds, external scrutiny, and public commitments can make it harder to cut corners. Critics reply that voluntary promises are most likely to weaken precisely when competitive pressure becomes strongest. The recent evolution of frontier-lab safety frameworks has become a real-world test of that concern. Anthropic [OpenAI]OpenAIupdating our preparedness frameworkcomOur updated Preparedness Framework15 Apr 2025 — Sharing our updated framework for measuring and protecting against severe harm from fr…
Whether this works in practice remains disputed. Supporters argue that predefined thresholds, external scrutiny, and public commitments can make it harder to cut corners. Critics reply that voluntary promises are most likely to weaken precisely when competitive pressure becomes strongest. The recent evolution of frontier-lab safety frameworks has become a real-world test of that concern. Anthropic [OpenAI]OpenAIupdating our preparedness frameworkcomOur updated Preparedness Framework15 Apr 2025 — Sharing our updated framework for measuring and protecting against severe harm from fr…
How responsible scaling policies are meant to work
Responsible scaling policies are governance frameworks that tie development and deployment decisions to assessments of model capability and risk. The basic logic is simple: as AI systems become more capable, the required level of safety, security, monitoring, and evaluation should also increase. If a model crosses predefined thresholds associated with catastrophic misuse or loss-of-control concerns, additional safeguards are supposed to become mandatory before deployment or further scaling continues. [Frontier Model Forum]frontiermodelforum.orgrisk taxonomy and thresholdsFrontier AI frameworks outline methodologies for identifying, managing and mitigating the potential for large-scale risks…Read more… [3Anthropic 3Anthropic]
Several frontier developers have adopted versions of this idea.
- Anthropic’s Responsible Scaling Policy uses AI Safety Levels (ASLs), inspired partly by biosafety levels, with increasingly demanding requirements as capabilities advance. [Anthropic]anthropic.coms responsible scaling policyAnthropicAnthropic's Responsible Scaling Policy19 Sept 2023 — Our RSP defines a framework called AI Safety Levels (ASL) for addressing ca…
- OpenAI’s Preparedness Framework defines tracked risk categories and capability thresholds intended to trigger stronger mitigations before deployment. [OpenAI CDN]cdn.openai.compreparedness framework v2OpenAI CDNPreparedness Framework15 Apr 2025 — Until now, our models' own limitations have given us confidence that, in the areas tracked…
- Industry-wide discussions within the Frontier Model Forum have similarly focused on defining thresholds that could justify deployment restrictions or pauses until safeguards improve. [Frontier Model Forum]frontiermodelforum.orgrisk taxonomy and thresholdsFrontier AI frameworks outline methodologies for identifying, managing and mitigating the potential for large-scale risks…Read more…
For people worried about AI doom, the attraction is clear. Launch races create incentives to move quickly. A policy that commits a lab in advance to specific actions can act as a brake. If a model appears capable of dangerous autonomous cyber activity, advanced biological assistance, or other catastrophic-risk behaviours, deployment would theoretically be delayed regardless of commercial incentives. [Frontier Model Forum]frontiermodelforum.orgrisk taxonomy and thresholdsFrontier AI frameworks outline methodologies for identifying, managing and mitigating the potential for large-scale risks…Read more… [Frontier]frontiermodelforum.orgrisk taxonomy and thresholdsFrontier AI frameworks outline methodologies for identifying, managing and mitigating the potential for large-scale risks…Read more…
In effect, responsible scaling policies try to convert safety from a discretionary choice into an organisational obligation.
Why pre-commitments may help during competitive pressure
The strongest argument for responsible scaling policies is not that they eliminate racing dynamics but that they change the decision environment.
Without predefined rules, a leadership team facing a major competitive threat might ask whether another month of testing is really necessary. With a public framework in place, the question becomes whether the organisation is willing to violate its own stated commitments. That difference can matter.
Several features are intended to strengthen resistance to launch pressure:
Public accountability. Once thresholds and commitments are published, outside researchers, journalists, governments, and employees can compare actions against promises. A quiet internal compromise becomes harder. [Anthropic]anthropic.comannouncing our updated responsible scaling policyAnthropicAnnouncing our updated Responsible Scaling Policy15 Oct 2024 — This update introduces a more flexible and nuanced approach to as… [LinkedIn]linkedin.comUpdated Responsible Scaling Policy: Enhanced…Anthropic has released Responsible Scaling Policy (RSP) 3.0, outlining a framework where…
Defined trigger points. Capability thresholds create decision rules before the heat of competition arrives. This reduces reliance on ad hoc judgement under pressure. Frontier Model Forum [METR]metr.orgcommon elementsMETRCommon Elements of Frontier AI Safety Policies16 Dec 2025 — The policies also outline commitments to conduct model evaluations assess…
Institutionalising safety work. Frameworks encourage investment in evaluations, red-teaming, monitoring, and security systems long before a crisis emerges. Safety becomes part of the development process rather than a last-minute review. [METR]metr.orgcommon elementsMETRCommon Elements of Frontier AI Safety Policies16 Dec 2025 — The policies also outline commitments to conduct model evaluations assess…
Creating industry expectations. If multiple frontier developers adopt similar frameworks, refusing to conduct evaluations or ignoring dangerous findings becomes more reputationally costly. [ailabwatch.org]ailabwatch.orgby several companies16 AI companies joined the Frontier AI Safety Commitments in May 2024, basically committing to make responsible scali…
From a doom-focused perspective, these mechanisms matter because many catastrophic-risk scenarios involve organisations gradually normalising risk-taking as capabilities advance. Formal commitments are intended to make that drift more difficult.
Where voluntary commitments can bend under pressure
The main objection is straightforward: a policy only constrains behaviour if the organisation continues to honour it when doing so becomes expensive.
This concern has become more prominent because some frontier safety frameworks have evolved over time rather than remaining fixed. Anthropic’s Responsible Scaling Policy, for example, has undergone multiple revisions. In early versions, the company emphasised commitments that could imply pausing development or deployment if safety measures lagged behind capability gains. By 2026, the company had revised its framework, arguing that unilateral restraint was increasingly difficult in a competitive environment and placing greater emphasis on transparency, risk reporting, and ongoing risk management. [Time]time.comexclusive anthropic drops flagship safety pledgeExclusive: Anthropic Drops Flagship Safety Pledge24 Feb 2026 — In 2023, Anthropic committed to never train an AI system unless it could g… [4Anthropic 4Anthropic]
Supporters of the change argue that adapting frameworks to reality is sensible and that transparency requirements can still improve safety. Critics see the revision as evidence of the underlying problem: when competitive incentives intensify, voluntary commitments may be rewritten rather than enforced. Anthropic [Business Insider]businessinsider.comanthropic changing safety policy 2026 2The company will no longer unilaterally pause or delay new AI model deployments when safety mechanisms lag, citing increased competition…
This is one of the central disputes within AI doom discussions. Skeptics of voluntary governance argue that launch races create a collective-action problem:
- A single lab may lose market position if it slows down.
- Executives know competitors may continue advancing.
- Investors and customers reward capability gains.
- Governments may prioritise national competitiveness.
Under those conditions, the temptation to weaken commitments can become substantial. [TechRadar]techradar.comanthropic drops its signature safety promise and rewrites ai guardrailsThis marked a significant policy shift from its original 2023 pledge that emphasized strong preconditions for AI development in order to… [LessWrong]lesswrong.comresponsible scaling policy v3 NarratedLessWrongResponsible Scaling Policy v324 Feb 2026 — Voluntary commitments and even regulation could be too hard to enforce across the boa… [3alignmentforum.org]alignmentforum.orgthoughts on responsible scaling policies and regulationVoluntary commitments are unlikely to be…Read more…
The concern is not necessarily deliberate bad faith. Rather, the same organisation that sincerely creates a safety framework may later conclude that strict adherence is no longer practical.

The deeper problem: who decides that a threshold has been crossed?
Even if a lab genuinely wants to follow its framework, implementation remains difficult.
Most frontier frameworks depend on evaluations. The organisation must determine whether a model has crossed a capability threshold that justifies stronger safeguards or deployment restrictions. Yet evaluating advanced systems is itself an active research problem. Researchers continue to debate how reliably current evaluations measure dangerous capabilities, strategic behaviour, or future performance. [Institute for AI Policy and Strategy]iaps.aievaluation awareness why frontier ai models are getting harder to testInstitute for AI Policy and StrategyEvaluation Awareness: Why Frontier AI Models Are Getting…31 Mar 2026 — If a capability evaluation…
This creates a subtle vulnerability.
If threshold assessments depend largely on internal testing, then the organisation may retain substantial discretion over whether a model is considered dangerous enough to trigger stronger requirements. Even a well-intentioned lab may face uncertainty, ambiguous evidence, or disagreement among experts.
For AI doom researchers concerned about deception, scheming, or loss of control, this uncertainty is especially important. A framework is only as strong as the evaluations that determine when its safeguards activate. If dangerous capabilities are under-detected, the policy may appear rigorous while failing to constrain genuinely risky systems. [Institute for AI Policy and Strategy]iaps.aievaluation awareness why frontier ai models are getting harder to testInstitute for AI Policy and StrategyEvaluation Awareness: Why Frontier AI Models Are Getting…31 Mar 2026 — If a capability evaluation…
What stronger release gates would need
Many analysts who support responsible scaling policies nevertheless argue that voluntary frameworks alone are unlikely to be sufficient.
Several additions are commonly proposed:
Independent evaluation. External assessors could verify capability claims and safety findings rather than relying solely on internal testing. This reduces the risk that commercial incentives influence threshold determinations. [arXiv]arxiv.orgarXivEvaluating AI Providers' Frontier Safety Frameworks30 Apr 2026 — OpenAI commits to "release information about our Preparedness Frame…
Clearer deployment restrictions. Frameworks become harder to reinterpret when consequences are tied to specific thresholds in advance. [Frontier Model Forum]frontiermodelforum.orgrisk taxonomy and thresholdsFrontier AI frameworks outline methodologies for identifying, managing and mitigating the potential for large-scale risks…Read more…
Transparency requirements. Publishing risk reports, evaluation results, and framework updates can make it easier for outsiders to detect weakening commitments. [Anthropic]anthropic.comresponsible scaling policy v3AnthropicResponsible Scaling Policy Version 3.024 Feb 2026 — We're releasing the third version of our Responsible Scaling Policy (RSP), t… [LinkedIn]linkedin.comDavid PereiraResponsible Scaling Policy Version 3.0Mostly just a lot of suggestions that match what regulators are trying to do to protect people from…
Cross-lab coordination. If multiple frontier developers accept similar rules, the competitive penalty for slowing down is reduced. This directly addresses launch-race incentives. [ailabwatch.org]ailabwatch.orgby several companies16 AI companies joined the Frontier AI Safety Commitments in May 2024, basically committing to make responsible scali…
Regulatory backing. Some researchers argue that the strongest safeguards require legal obligations rather than voluntary promises. In this view, responsible scaling policies are valuable prototypes but cannot solve coordination problems on their own. [alignmentforum.org]alignmentforum.orgthoughts on responsible scaling policies and regulationVoluntary commitments are unlikely to be…Read more…
The underlying goal is to move from “a company promises to be careful” toward systems where breaking safety commitments carries meaningful costs.

What this means for AI doom arguments
Responsible scaling policies occupy an unusual place in AI doom debates. They are among the most concrete proposals for managing catastrophic AI risks before they emerge, yet they also illustrate the difficulties of relying on self-governance.
Optimists view them as evidence that frontier developers are beginning to treat catastrophic-risk scenarios seriously and are creating mechanisms that can slow unsafe deployment. Pessimists see them as useful but fragile safeguards that may weaken when commercial, geopolitical, or organisational pressures become intense. Anthropic [OpenAI]OpenAIupdating our preparedness frameworkcomOur updated Preparedness Framework15 Apr 2025 — Sharing our updated framework for measuring and protecting against severe harm from fr…
The strongest conclusion supported by current evidence is neither that responsible scaling policies will stop launch races nor that they are meaningless. Rather, they appear capable of increasing caution and improving accountability, but their ability to resist a serious race depends on factors outside the policy itself: independent scrutiny, robust evaluations, coordination among major actors, and willingness to accept competitive costs when safety concerns arise. [arXiv]arxiv.orgarXivEvaluating AI Providers' Frontier Safety Frameworks30 Apr 2026 — OpenAI commits to "release information about our Preparedness Frame… [Frontier]frontiermodelforum.orgrisk taxonomy and thresholdsFrontier AI frameworks outline methodologies for identifying, managing and mitigating the potential for large-scale risks…Read more…
For readers concerned about AI doom and p(doom), that distinction matters. Responsible scaling policies may be one of the few existing tools designed specifically to slow dangerous deployment. The unresolved question is whether voluntary commitments remain strong enough when the incentives to abandon them become greatest. [TechRadar]techradar.comanthropic drops its signature safety promise and rewrites ai guardrailsThis marked a significant policy shift from its original 2023 pledge that emphasized strong preconditions for AI development in order to… [LessWrong]lesswrong.comresponsible scaling policy v324 Feb 2026 — Today, Anthropic released its Responsible Scaling Policy 3.0. The official announcement discusses the high-level thinking b… [3alignmentforum.org]alignmentforum.orgthoughts on responsible scaling policies and regulationVoluntary commitments are unlikely to be…Read more…
Amazon book picks
Further Reading
Books and field guides related to Can lab safety promises survive launch races?. Use these as the next step if you want deeper reading beyond the article.
Human Compatible
Directly addresses governance, control, and incentives around advanced AI development.
The Coming Wave
Focuses on containment, governance, and managing powerful technologies under competitive pressure.
The Alignment Problem
Provides background on why safety commitments and oversight mechanisms matter.
Superintelligence
Frames the rationale for stronger safeguards as capabilities increase.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.






Endnotes
-
Source: anthropic.com
Link: https://www.anthropic.com/responsible-scaling-policySource snippet
AnthropicAnthropic's Responsible Scaling PolicyIn our Responsible Scaling Policy, reaching certain Capability Thresholds requires us to u...
-
Source: anthropic.com
Title: s responsible scaling policy
Link: https://www.anthropic.com/news/anthropics-responsible-scaling-policySource snippet
AnthropicAnthropic's Responsible Scaling Policy19 Sept 2023 — Our RSP defines a framework called AI Safety Levels (ASL) for addressing ca...
-
Source: anthropic.com
Title: announcing our updated responsible scaling policy
Link: https://www.anthropic.com/news/announcing-our-updated-responsible-scaling-policySource snippet
AnthropicAnnouncing our updated Responsible Scaling Policy15 Oct 2024 — This update introduces a more flexible and nuanced approach to as...
-
Source: OpenAI
Title: updating our preparedness framework
Link: https://openai.com/index/updating-our-preparedness-framework/Source snippet
comOur updated Preparedness Framework15 Apr 2025 — Sharing our updated framework for measuring and protecting against severe harm from fr...
-
Source: alignmentforum.org
Title: thoughts on responsible scaling policies and regulation
Link: https://www.alignmentforum.org/posts/dxgEaDrEBkkE96CXr/thoughts-on-responsible-scaling-policies-and-regulationSource snippet
Voluntary commitments are unlikely to be...Read more...
-
Source: cdn.openai.com
Title: preparedness framework v2
Link: https://cdn.openai.com/pdf/18a02b5d-6b67-4cec-ab64-68cdfbddebcd/preparedness-framework-v2.pdfSource snippet
OpenAI CDNPreparedness Framework15 Apr 2025 — Until now, our models' own limitations have given us confidence that, in the areas tracked...
-
Source: metr.org
Title: common elements
Link: https://metr.org/common-elementsSource snippet
METRCommon Elements of Frontier AI Safety Policies16 Dec 2025 — The policies also outline commitments to conduct model evaluations assess...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/anthropicresearch_responsible-scaling-policy-version-30-activity-7432159929794269184-IBjZSource snippet
Updated Responsible Scaling Policy: Enhanced...Anthropic has released Responsible Scaling Policy (RSP) 3.0, outlining a framework where...
-
Source: ailabwatch.org
Link: https://ailabwatch.org/resources/commitmentsSource snippet
by several companies16 AI companies joined the Frontier AI Safety Commitments in May 2024, basically committing to make responsible scali...
Published: May 2024
-
Source: anthropic.com
Title: responsible scaling policy v3
Link: https://www.anthropic.com/news/responsible-scaling-policy-v3Source snippet
AnthropicResponsible Scaling Policy Version 3.024 Feb 2026 — We're releasing the third version of our Responsible Scaling Policy (RSP), t...
-
Source: time.com
Title: exclusive anthropic drops flagship safety pledge
Link: https://time.com/7380854/exclusive-anthropic-drops-flagship-safety-pledge/Source snippet
Exclusive: Anthropic Drops Flagship Safety Pledge24 Feb 2026 — In 2023, Anthropic committed to never train an AI system unless it could g...
-
Source: techradar.com
Title: anthropic drops its signature safety promise and rewrites ai guardrails
Link: https://www.techradar.com/ai-platforms-assistants/anthropic-drops-its-signature-safety-promise-and-rewrites-ai-guardrailsSource snippet
This marked a significant policy shift from its original 2023 pledge that emphasized strong preconditions for AI development in order to...
-
Source: lesswrong.com
Title: responsible scaling policy v3 Narrated
Link: https://www.lesswrong.com/posts/HzKuzrKfaDJvQqmjh/responsible-scaling-policy-v3—NarratedSource snippet
LessWrongResponsible Scaling Policy v324 Feb 2026 — Voluntary commitments and even regulation could be too hard to enforce across the boa...
-
Source: arxiv.org
Link: https://arxiv.org/html/2512.01166v5Source snippet
arXivEvaluating AI Providers' Frontier Safety Frameworks30 Apr 2026 — OpenAI commits to "release information about our Preparedness Frame...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2509.24394Source snippet
arXivThe 2025 OpenAI Preparedness Framework does not guarantee any AI risk mitigation practices: a proof-of-concept for affordance analys...
-
Source: arxiv.org
Link: https://arxiv.org/abs/2502.06656 -
Source: OpenAI
Title: introducing gpt 5 5
Link: https://openai.com/index/introducing-gpt-5-5/Source snippet
comIntroducing GPT-5.523 Apr 2026 — On [Artificial]({{ 'artificial-goals/' | relative_url }}) Analysis's Coding Index, GPT‑5.5 delivers state-of-the-art intelligence at half the cos...
-
Source: anthropic.com
Title: rsp v3 0
Link: https://anthropic.com/responsible-scaling-policy/rsp-v3-0Source snippet
Anthropic's Responsible Scaling Policy (version 3.0)24 Feb 2026 — Our Responsible Scaling Policy (RSP) is our voluntary framework for man...
-
Source: linkedin.com
Title: David Pereira
Link: https://www.linkedin.com/posts/dpereirapaz_responsible-scaling-policy-version-30-activity-7432343274989924352-fivzSource snippet
Responsible Scaling Policy Version 3.0Mostly just a lot of suggestions that match what regulators are trying to do to protect people from...
-
Source: linkedin.com
Title: Who Gets to Stop an Unsafe AI Release?
Link: https://www.linkedin.com/pulse/who-gets-stop-unsafe-ai-release-ron-bodkin-iingeSource snippet
Ron BodkinSelf-governance is failing under frontier conditions. Both Anthropic and OpenAI have weakened voluntary safety commitments over...
-
Source: linkedin.com
Title: fdegni openai preparedness framework v2 april activity 7318113212137201664 EGnp
Link: https://www.linkedin.com/posts/fdegni_openai-preparedness-framework-v2-april-activity-7318113212137201664-EGnpSource snippet
Preparedness Framework v2 / April 2015 | Fabrizio DegniEthical Responsibility in AI Deployment: OpenAI's proactive threat detection under...
Published: April 2015
-
Source: arxiv.org
Link: https://arxiv.org/pdf/2509.24394Source snippet
Understanding which AI...Read m...
-
Source: lesswrong.com
Title: responsible scaling policy v3
Link: https://www.lesswrong.com/posts/HzKuzrKfaDJvQqmjh/responsible-scaling-policy-v3Source snippet
24 Feb 2026 — Today, Anthropic released its Responsible Scaling Policy 3.0. The official announcement discusses the high-level thinking b...
-
Source: lesswrong.com
Link: https://www.lesswrong.com/posts/uzoDihenMRximhGZn/a-brief-assessment-of-openai-s-preparedness-framework-andSource snippet
A Brief Assessment of OpenAI's Preparedness Framework...22 Jan 2024 — Implement rigorous incident reporting & disclosure mechanisms with...
-
Source: governance.ai
Link: https://www.governance.ai/analysis/anthropics-rsp-v3-0-how-it-works-whats-changed-and-some-reflectionsSource snippet
Anthropic's RSP v3.0: How it Works, What's Changed, and...17 Mar 2026 — The RSP describes how Anthropic intends to assess and mitigate p...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=9IhcygeoKRsSource snippet
Anthropic Vs. OpenAI: How Safety Became The Advantage In AI...
-
Source: youtube.com
Title: Anthropic Vs. Open AI: How Safety Became The Advantage In AI
Link: https://www.youtube.com/watch?v=JILSzhssMskSource snippet
OpenAI's New Safety Preparedness Framework...
-
Source: youtube.com
Title: Open AI’s New Safety Preparedness Framework
Link: https://www.youtube.com/watch?v=GVE2zPtHZvYSource snippet
OpenAI plans new safety measures amid legal pressure...
-
Source: youtube.com
Title: Open AI plans new safety measures amid legal pressure
Link: https://www.youtube.com/watch?v=d68AoN9d6RQSource snippet
What OpenAI Doesn’t Want You to Know...
-
Source: frontiermodelforum.org
Title: risk taxonomy and thresholds
Link: https://www.frontiermodelforum.org/technical-reports/risk-taxonomy-and-thresholds/Source snippet
Frontier AI frameworks outline methodologies for identifying, managing and mitigating the potential for large-scale risks...Read more...
-
Source: frontiermodelforum.org
Title: managing advanced cyber risks in frontier ai frameworks
Link: https://www.frontiermodelforum.org/technical-reports/managing-advanced-cyber-risks-in-frontier-ai-frameworks/Source snippet
13 Feb 2026 — Frontier AI frameworks use thresholds to help determine when additional assessments or safeguards become necessary, and whe...
-
Source: businessinsider.com
Title: anthropic changing safety policy 2026 2
Link: https://www.businessinsider.com/anthropic-changing-safety-policy-2026-2Source snippet
The company will no longer unilaterally pause or delay new AI model deployments when safety mechanisms lag, citing increased competition...
-
Source: iaps.ai
Title: [evaluation awareness]({{ ‘evaluation-awareness/’ | relative_url }}) why frontier ai models are getting harder to test
Link: https://www.iaps.ai/research/evaluation-awareness-why-frontier-ai-models-are-getting-harder-to-testSource snippet
Institute for AI Policy and StrategyEvaluation Awareness: Why Frontier AI Models Are Getting...31 Mar 2026 — If a capability evaluation...
-
Source: forum.effectivealtruism.org
Title: openai preparedness framework
Link: https://forum.effectivealtruism.org/posts/p6Wccw2Gg3ESLMvRr/openai-preparedness-frameworkSource snippet
· Stronger commitment about external evals/red-teaming/risk-assessment of private models (and maybe...Read more...
-
Source: callsphere.ai
Title: Anthropic’s Updated Responsible Scaling Policy: Practical Implications
Link: https://callsphere.ai/blog/td30-anth-safety-rsp-updateSource snippet
April 18, 2026 — Anthropic responsible scaling is the most recent step in Anthropic's effort to make Claude more capable, more reliable...
Published: April 18, 2026
-
Source: thezvi.substack.com
Title: anthropic responsible scaling policy
Link: https://thezvi.substack.com/p/anthropic-responsible-scaling-policySource snippet
Responsible Scaling Policy v3: A Matter of TrustThe Responsible Scaling Policy is Anthropic's commitments regarding when and under what c...
-
Source: thezvi.substack.com
Title: openai preparedness framework 20
Link: https://thezvi.substack.com/p/openai-preparedness-framework-20Source snippet
Preparedness Framework 2.0The Preparedness Framework is OpenAI's approach to tracking and preparing for frontier capabilities that create...
-
Source: verifywise.ai
Link: https://verifywise.ai/ai-governance-library/policies-and-internal-governance/anthropic-responsible-scaling-policySource snippet
Anthropic Responsible Scaling PolicyAnthropic's Responsible Scaling Policy defines AI Safety Levels (ASL) based on model capabilities and...
-
Source: facebook.com
Link: https://www.facebook.com/cheddar/posts/anthropic-announced-it-is-loosening-its-core-ai-safety-commitments-replacing-its/1340685084760692/Source snippet
ts binding Responsible Scaling Policy with a more flexible...
-
Source: safer-ai.org
Title: anthropics responsible scaling policy update makes a step backwards
Link: https://www.safer-ai.org/anthropics-responsible-scaling-policy-update-makes-a-step-backwardsSource snippet
Anthropic's Responsible Scaling Policy Update Makes a...23 Oct 2024 — By allowing more leeway to decide if a model meets thresholds, Ant...
-
Source: ea-crux-project.vercel.app
Title: responsible scaling policies
Link: https://ea-crux-project.vercel.app/knowledge-base/responses/responsible-scaling-policies/Source snippet
29 Jan 2026 — Current evidence suggests RSPs cover approximately 60-70% of frontier AI development across 3-4 major laboratories, with es...
-
Source: digital.nemko.com
Title: anthropic ai safety strategy what enterprises must know
Link: https://digital.nemko.com/news/anthropic-ai-safety-strategy-what-enterprises-must-knowSource snippet
details Responsible Scaling Policy for frontier AI25 Aug 2025 — Anthropic AI safety strategy posture has been shaped by its leadership te...
Additional References
-
Source: iaps.ai
Link: https://www.iaps.ai/research/responsible-scalingSource snippet
March 11, 2024 — “Responsible capability scaling” is the specification of progressively higher levels of risk, roughly corresponding to m...
Published: March 11, 2024
-
Source: researchgate.net
Title: 390042099 Anthropic Responsible Scaling Policy
Link: https://www.researchgate.net/publication/390042099_Anthropic_Responsible_Scaling_PolicySource snippet
(PDF) Anthropic: Responsible Scaling PolicyIn September 2023, we released our Responsible Scaling Policy (RSP), a public commitment not t...
Published: September 2023
-
Source: bbfc.co.uk
Title: the commitments q29sbgvjdglvbjpwwc0zmtmznte
Link: https://www.bbfc.co.uk/release/the-commitments-q29sbgvjdglvbjpwwc0zmtmznteSource snippet
The CommitmentsTHE COMMITMENTS is a musical comedy drama from 1991 in which an unemployed man from Dublin enlists a group of young workin...
-
Source: forum.effectivealtruism.org
Title: responsible scaling policy v3 1
Link: https://forum.effectivealtruism.org/posts/DGZNAGL2FNJfftwgE/responsible-scaling-policy-v3-1Source snippet
Scaling Policy v324 Feb 2026 — But it's been easy to get the impression that the RSP is “binding ourselves to the mast” and committing to...
-
Source: Wikipedia
Title: The Commitments (film)
Link: https://en.wikipedia.org/wiki/The_Commitments_%28film%29Source snippet
The Commitments (film)The Commitments is a 1991 musical comedy-drama film based on the 1987 novel by Roddy Doyle. It was directed by A...
-
Source: enkryptai.com
Title: frontier safety frameworks comprehensive overview
Link: https://www.enkryptai.com/blog/frontier-safety-frameworks-comprehensive-overviewSource snippet
Frontier Safety Frameworks — A Comprehensive Picture17 Jul 2025 — OpenAI's Preparedness Framework focuses on the identification of Tracke...
-
Source: youtube.com
Title: What Open AI Doesn’t Want You to Know
Link: https://www.youtube.com/watch?v=DUfSl2fZ_E8Source snippet
Responsible Scaling Policies AI safety race Anthropic ASL Zac Hatfield-Dodds | Anthropic’s Responsible Scaling Policy @ Vision Weekend US...
-
Source: imdb.com
Link: https://www.imdb.com/title/tt0101605/Source snippet
The Commitments (1991)Jimmy Rabbitte, an unemployed Dublin boy, decides to put together a soul band made up entirely of the Irish working...
-
Source: ratings.safer-ai.org
Link: https://ratings.safer-ai.org/company/openai/Source snippet
– Risk Management Ratings - SaferAITheir deployment mitigation thresholds, characterised by Robustness, Usage Monitoring, and Trust-based...
-
Source: youtube.com
Title: Lex Clips
Link: https://www.youtube.com/watch?v=9V6tWC4CdFQSource snippet
MIT Explains the 12 Possible Endings for AI Species | Documenting AGI...
Topic Tree