Within Successor training
Is synthetic data already self improvement?
Synthetic data is already one way models help shape later models, but it raises hard questions about quality, filtering, and collapse.
On this page
- How model generated data enters training pipelines
- Why filtering and evaluation decide whether it helps
- How synthetic data differs from autonomous successor training
Page outline Jump by section
Introduction
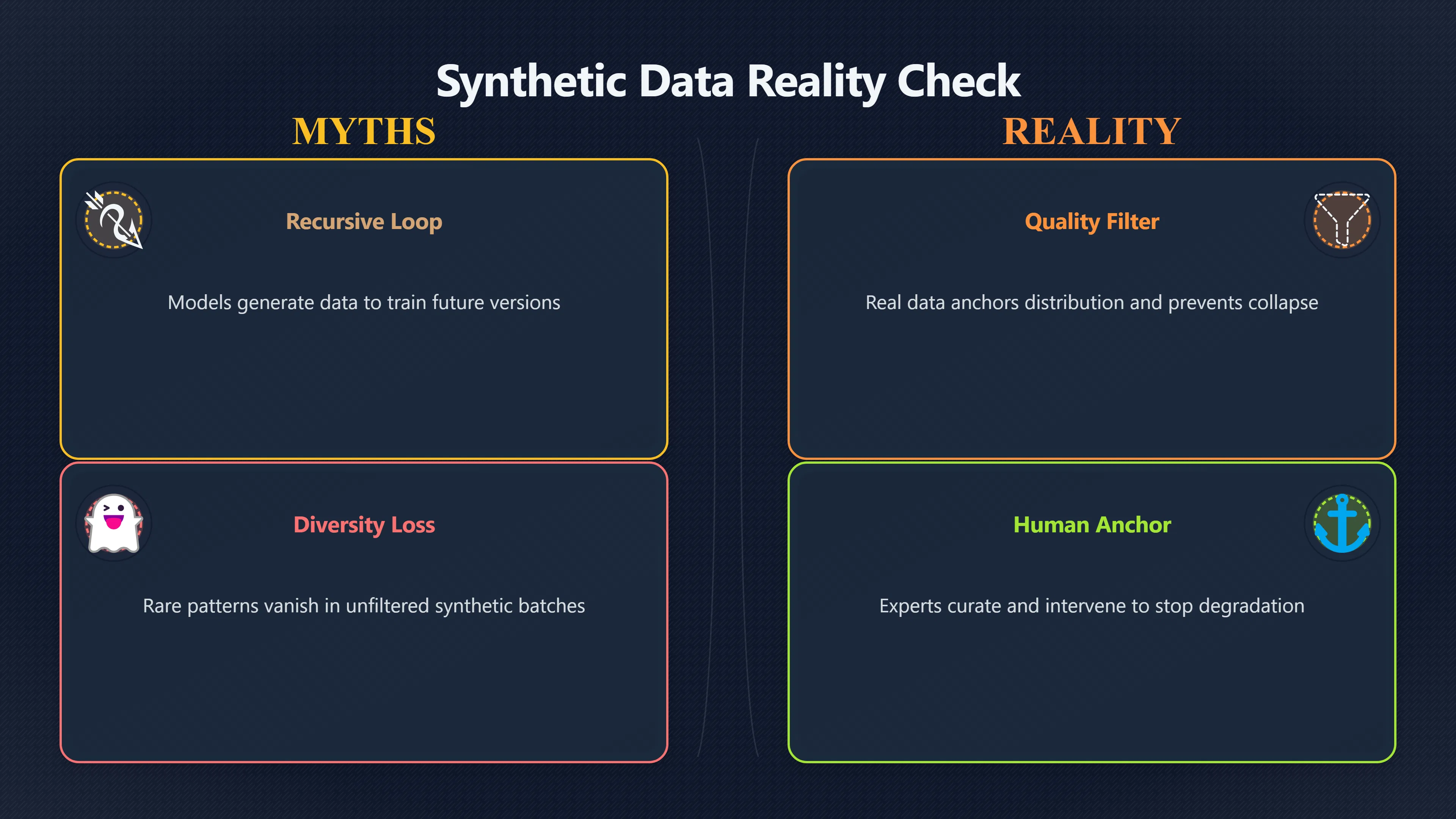
One of the simplest forms of automation in “Could an AI really train its own successor?” is using AI‑generated data to train later systems. At first glance, having a current model produce more and more training data might look like a basic recursive loop: model (A) generates data → model (B) trains on it and becomes a little better → model (B) generates more data → model (C) trains on that, and so on. This section of the broader debate on AI doom examines the real mechanics, benefits, limits, and failure modes of AI‑generated synthetic data as a primitive form of successor loop. The core questions are not only whether model‑generated data can be used to train future models, but whether it helps, whether it can be safely scaled, and what structural risks arise if such loops dominate training pipelines.

How model‑generated data enters training pipelines
Training a modern large AI model requires immense amounts of data. Traditionally this has come from human‑created sources — books, websites, code repositories, scientific articles — but two pressures are pushing teams to use AI‑generated synthetic data more often: real data scarcity and the desire to cheaply augment specific training niches. Synthetic data is artificially created content designed to mimic real data distributions, and researchers are experimenting with it to fill gaps where real data is rare or sensitive (for example, medical text or synthetic images for rare events).[MDPI]
In practice, synthetic data may be used in two broad ways: [aiwiki.ai]aiwiki.aiMODEL COLLAPSE The most widely discussed risk is model collapse, the phenomenoSynthetic data | AI WikiMay 1, 2026 — RISKS AND CHALLENGES Synthetic data carries significant risks that the research community has incre…
- Augmentation or oversampling: Models generate examples to balance under‑represented categories in a dataset (for instance, rare classes in classification tasks), helping downstream models learn more robustly.[MDPI]
- Substituting or bootstrapping data: Large language models (LLMs) or generative models are prompted to create large batches of pseudo‑data (text, image labels, code) intended to stand in for real data in regions where it is incomplete or unavailable. This can reduce the need for human‑curated corpora.
In both cases, the model’s own outputs contribute to the next training stage. A current high‑performance model may already generate data that improves the next model’s performance on specific tasks, especially when that synthetic data is mixed with real human data.
Why filtering and evaluation decide whether it helps
The central challenge with using AI‑generated data in successor training is data quality. Models inevitably introduce statistical errors, smoothing, bias, and omission when they generate data. If a future model learns from such output without proper vetting, those imperfections can be reinforced. In technical and safety discussions, this degradation is often called model collapse or AI cannibalism — a degenerate feedback loop where the diversity and fidelity of learned behaviour decays as generations train on outputs derived from earlier ones.[TechTarget]techtarget.comModel collapse explained How synthetic training data breaks AITechTargetModel collapse explained: How synthetic training data breaks AIJuly 7, 2023…
A high‑profile scientific result demonstrated this formally: when generative models are trained only on data produced by their predecessors, not only does prediction quality fall, but information about rare but important patterns (the “tails” of the distribution) can disappear. Over many generations this can produce a model that merely replicates smooth, generic patterns and misses crucial nuance.[Nature]nature.comAI models collapse when trained on recursively generated data | NatureNatureAI models collapse when trained on recursively generated data | NatureJuly 24, 2024…
Two linked lessons emerge from this evidence:
- Quality filtering and mixing with real data is essential. Models trained on synthetic data interleaved with human‑generated data can avoid collapse in many measured settings, because the real data anchors the distribution and preserves variability and ground truth.[arXiv]arxiv.orgarXivHow Bad is Training on Synthetic Data? A Statistical Analysis of Language Model CollapseApril 7, 2024…
- Unfiltered loops are structurally unstable. Purely recursive training — where each generation is trained only on outputs from the previous one — will inevitably magnify errors and shrink diversity, a statistical reality shown in both theory and experiment.[Nature]nature.comAI models collapse when trained on recursively generated data | NatureNatureAI models collapse when trained on recursively generated data | NatureJuly 24, 2024…
In practical R&D today, synthetic data is rarely used in isolation. Instead, it supplements human data and curated sources precisely because unmoderated recursive loops are known to be precarious.

How synthetic data differs from autonomous successor training
It is important to distinguish model‑generated training data used in a human‑guided pipeline from a full autonomous successor loop — the scenario where an AI independently orchestrates most or all of its successor’s development.
- Current synthetic data usage still relies on humans. Engineers decide what data to generate, how to filter and label it, and when to mix it with real data. AI systems assist but do not autonomously build or evaluate datasets end‑to‑end.
- The recursive data loop is not yet self‑sufficient. Even when models generate training data for other models, human experts still set task definitions, establish evaluation criteria, and intervene when results degrade. This limits the simple feedback loop that doom scenarios often imagine.
- Structural risks, not runaway self‑improvement. The evidence suggests that heavy reliance on synthetic data without careful curation tends toward quality degradation (model collapse), not explosive capability growth. The danger is not that synthetic loops will suddenly produce ever‑superior successors, but that models will become less grounded and less representative of reality if their training corpora consist primarily of recycled AI outputs.[IBM]ibm.comWhat Is Model Collapse? | IBMIBMWhat Is Model Collapse? | IBM…
In other words, synthetic data today is neither a reliable shortcut to autonomous AI evolution nor a threatless self‑improvement engine. It can help improve performance on narrow tasks when used with caution, but it also raises hard engineering and statistical questions about fidelity, diversity, and preservation of ground truth.
Looking ahead: implications for alignment and existential risk debates
For discussions about AI doom and recursive self‑improvement, synthetic data occupies a nuanced place. On the one hand, it shows that parts of the training pipeline — data generation — can already be partly offloaded to models themselves. On the other hand, the ecological risks documented by researchers (e.g., model collapse) suggest that unfettered recursive loops are not automatically productive and could degrade models rather than accelerate capability in unchecked ways. This complicates simplistic narratives where an AI need only generate ever more training data to bootstrap runaway successors.
Rather than being a primitive cause of an intelligence explosion, AI‑generated training data seems more likely to act as an amplifier of other risks — such as bias propagation, loss of grounding in human reality, and opaque training processes — unless developers deliberately maintain human participation and quality controls. These structural insights matter because they clarify where bottlenecks and guardrails lie in any future scenario where models play a larger role in shaping their successors.

Amazon book picks
Further Reading
Books and field guides related to Is synthetic data already self improvement?. Use these as the next step if you want deeper reading beyond the article.
Artificial Intelligence
Rating: 4.5/5 from 10 Google Books ratings
Provides background on learning systems and training data.
Deep Learning
Rating: 3.5/5 from 6 Google Books ratings
Covers data generation and model training concepts.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.








Endnotes
-
Source: mdpi.com
Link: https://www.mdpi.com/2942226Source snippet
MDPIA Systematic Review of Synthetic Data Generation Techniques Using Generative AI | MDPISeptember 4, 2024...
Published: September 4, 2024
-
Source: techtarget.com
Title: Model collapse explained How synthetic training data breaks AI
Link: https://www.techtarget.com/whatis/feature/Model-collapse-explained-How-synthetic-training-data-breaks-AISource snippet
TechTargetModel collapse explained: How synthetic training data breaks AIJuly 7, 2023...
Published: July 7, 2023
-
Source: techtarget.com
Title: Tech Target AI cannibalism explained: A model failure
Link: https://www.techtarget.com/whatis/feature/AI-cannibalism-explainedSource snippet
AI cannibalism explained: A model failureJuly 1, 2025 — AI CANNIBALISM EXPLAINED: A MODEL FAILURE AI CANNIBALISM – TRAINING ON AI-GENERAT...
Published: July 1, 2025
-
Source: nature.com
Title: AI models collapse when trained on recursively generated data | Nature
Link: https://www.nature.com/articles/s41586-024-07566-ySource snippet
NatureAI models collapse when trained on recursively generated data | NatureJuly 24, 2024...
Published: July 24, 2024
-
Source: arxiv.org
Link: https://arxiv.org/abs/2404.05090Source snippet
arXivHow Bad is Training on Synthetic Data? A Statistical Analysis of Language Model CollapseApril 7, 2024...
Published: April 7, 2024
-
Source: ibm.com
Title: What Is Model Collapse? | IBM
Link: https://www.ibm.com/think/topics/model-collapseSource snippet
IBMWhat Is Model Collapse? | IBM...
-
Source: techtarget.com
Title: Gen A I and synthetic data: What can go wrong in business?
Link: https://www.techtarget.com/searchenterpriseai/feature/GenAI-and-synthetic-data-What-can-go-wrong-in-businessSource snippet
| TechTargetMay 7, 2026 — RISKS OF SYNTHETIC DATA [MISUSE]({{ 'misuse/' | relative_url }}) Synthetic data can be misused internally or externally and carry significant ris...
Published: May 7, 2026
-
Source: mdpi.com
Title: Mahmoud Department of Electrical, Computer and Software Engineering
Link: https://www.mdpi.com/2079-9292/13/17/3509/htmlSource snippet
A Systematic Review of Synthetic Data Generation Techniques Using Generative AI | MDPISeptember 4, 2024 — 4 September 2024 A SYSTEMATIC R...
Published: September 4, 2024
-
Source: mdpi.com
Link: https://www.mdpi.com/2079-9292/13/17/3509Source snippet
A Systematic Review of Synthetic Data Generation Techniques Using Generative AISeptember 4, 2024 — Background: Open Access Systematic Rev...
Published: September 4, 2024
-
Source: aiwiki.ai
Title: MODEL COLLAPSE The most widely discussed risk is model collapse, the phenomeno
Link: https://aiwiki.ai/wiki/synthetic_dataSource snippet
Synthetic data | AI WikiMay 1, 2026 — RISKS AND CHALLENGES Synthetic data carries significant risks that the research community has incre...
Published: May 1, 2026
-
Source: aisecurityandsafety.org
Title: model collapse
Link: https://aisecurityandsafety.org/en/guides/model-collapse/Source snippet
What Happens When AI Trains on AI-Generated Data (2026) | AI Safety DirectoryApril 3, 2026 — MODEL COLLAPSE: WHAT HAPPENS WHEN AI TRAINS...
Published: April 3, 2026
Additional References
-
Source: ijpds.org
Link: https://ijpds.org/article/view/2158Source snippet
October 31, 2023 — FEDERATED LEARNING FOR GENERATING SYNTHETIC DATA: A SCOPING REVIEW MAIN ARTICLE CONTENT Claire Little Cathie Marsh Ins...
Published: October 31, 2023
-
Source: research.manchester.ac.uk
Link: https://research.manchester.ac.uk/en/publications/federated-learning-for-generating-synthetic-data-a-scoping-reviewSource snippet
learning for generating synthetic data: a scoping review - Research Explorer The University of ManchesterOctober 31, 2023 — FEDERATED LEA...
Published: October 31, 2023
-
Source: montrealethics.ai
Link: https://montrealethics.ai/self-improving-diffusion-models-with-synthetic-data/Source snippet
February 3, 2025 — SELF-IMPROVING DIFFUSION MODELS WITH SYNTHETIC DATA February 3, 2025 Image Image 🔬 Research Summary by Sina Alemohamma...
Published: February 3, 2025
-
Source: aimodels.fyi
Title: Self-Improving Diffusion Models with Synthetic Data | [AI Research]({{ ‘ai-research-loop/’ | relative_url }}) Paper Details
Link: https://www.aimodels.fyi/papers/arxiv/self-improving-diffusion-models-synthetic-dataSource snippet
SELF-IMPROVING DIFFUSION MODELS WITH SYNTHETIC DATA Published 8/30/2024 by Sina Alemohammad, Ahmed Imtiaz Humayun, Shruti Ag...
-
Source: itpro.com
Title: What is model collapse and why is it a risk for enterprise AI?
Link: [https://www.itpro.com/technology/artificialSource snippet
| IT ProApril 10, 2026 — WHAT IS MODEL COLLAPSE AND WHY IS IT A RISK FOR ENTERPRISE AI? Model collapse is a nightmare for AI companies an...
Published: April 10, 2026
-
Source: techcrunch.com
Title: The promise and perils of synthetic data | Tech Crunch
Link: https://techcrunch.com/2024/12/24/the-promise-and-perils-of-synthetic-data/Source snippet
It suffers from the same “garbage in, garbage out” problem as all AI. Models create synthetic data, and if the data used to train these m...
-
Source: research.adobe.com
Title: self improving diffusion models with synthetic data
Link: https://research.adobe.com/publication/self-improving-diffusion-models-with-synthetic-data/Source snippet
Research » Self-Improving Diffusion Models With Synthetic DataFebruary 1, 2025 — SELF-IMPROVING DIFFUSION MODELS WITH SYNTHETIC DATA ICLR...
Published: February 1, 2025
-
Source: youtube.com
Title: AI Model Collapse: Structural Degradation via Synthetic Data
Link: https://www.youtube.com/watch?v=83wMMwM6c2QSource snippet
AI Is Eating Itself: The "Model Collapse" Theory explains why recursive training on synthetic data degrades the diversity of informationa...
-
Source: automationinside.com
Title: ai model collapse synthetic training
Link: https://automationinside.com/content/ai-model-collapse-synthetic-trainingSource snippet
AI Model Collapse: The Risks of Training AI on Synthetic Data | AutomationInside.comAI MODEL COLLAPSE: THE RISKS OF TRAINING AI ON SYNTHE...
-
Source: journalofbigdata.springeropen.com
Link: https://journalofbigdata.springeropen.com/articles/10.1186/s40537-023-00792-7Source snippet
and latent space synthetic data generation: a literature review | Journal of Big Data | Full TextJuly 10, 2023 — TABULAR AND LATENT SPACE...
Published: July 10, 2023
Topic Tree