Within Governance
Should Frontier Models Pass Safety Checks First?
Some proposals would require risk assessments, red-teaming and safety testing before the largest AI projects proceed.
On this page
- Pre Training Risk Assessments
- Independent Red Teaming Requirements
- What Happens When Risks Exceed Limits
Page outline Jump by section
Introduction
One of the most prominent proposals within frontier AI governance is that the most powerful models should pass formal safety checks before training proceeds or before a training run is allowed to continue beyond defined thresholds. The idea is simple: if advanced AI systems could eventually create existential risks through loss of control, dangerous autonomy, deception, or catastrophic misuse, waiting until after a model has been built may be too late. Instead, developers would have to conduct structured risk assessments, submit to independent testing, and demonstrate that identified hazards are being managed before moving forward. [GOV.UK]GOV.UKfrontier ai safety commitments ai seoul summit 2024Frontier AI Safety Commitments, AI Seoul Summit 20247 Feb 2025 — Outcome 1. Organisations effectively identify, assess and manage risks w…
 Supporters argue that mandatory evaluations could create an early-warning system for dangerous capabilities and reduce incentives to race ahead without adequate precautions. Critics counter that current evaluation methods remain immature, that future risks may be difficult to predict before a model exists, and that mandatory reviews could slow beneficial innovation without reliably preventing catastrophe. The debate therefore centres not on whether testing is useful, but on whether it should become a legal prerequisite for frontier AI development. [International AI Safety Report]internationalaisafetyreport.orginternational ai safety report 2026International AI Safety ReportInternational AI Safety Report 20263 Feb 2026 — In 2025, 12 companies published or updated their Frontier A…
Supporters argue that mandatory evaluations could create an early-warning system for dangerous capabilities and reduce incentives to race ahead without adequate precautions. Critics counter that current evaluation methods remain immature, that future risks may be difficult to predict before a model exists, and that mandatory reviews could slow beneficial innovation without reliably preventing catastrophe. The debate therefore centres not on whether testing is useful, but on whether it should become a legal prerequisite for frontier AI development. [International AI Safety Report]internationalaisafetyreport.orginternational ai safety report 2026International AI Safety ReportInternational AI Safety Report 20263 Feb 2026 — In 2025, 12 companies published or updated their Frontier A…
Why Test Before Training Rather Than After?
In most industries, safety checks happen before potentially dangerous systems are deployed. Frontier AI proposals push this logic further upstream. Instead of waiting until a model is completed, regulators or independent reviewers could examine the planned training run itself.
From an AI doom perspective, the concern is that some capabilities may emerge unexpectedly during training. If a model reaches a level where it can autonomously conduct cyber operations, help design biological weapons, deceive supervisors, or assist in accelerating further AI development, the opportunity to prevent those capabilities may already have passed. Advocates therefore argue that risk reviews should occur before the largest training runs begin and again at predefined milestones during development. Frontier Model Forum [2metr.org]metr.orgcommon elementsof Frontier AI Safety Policies16 Dec 2025 — To manage these risks effectively, the policies include evaluations designed to elicit the fu…
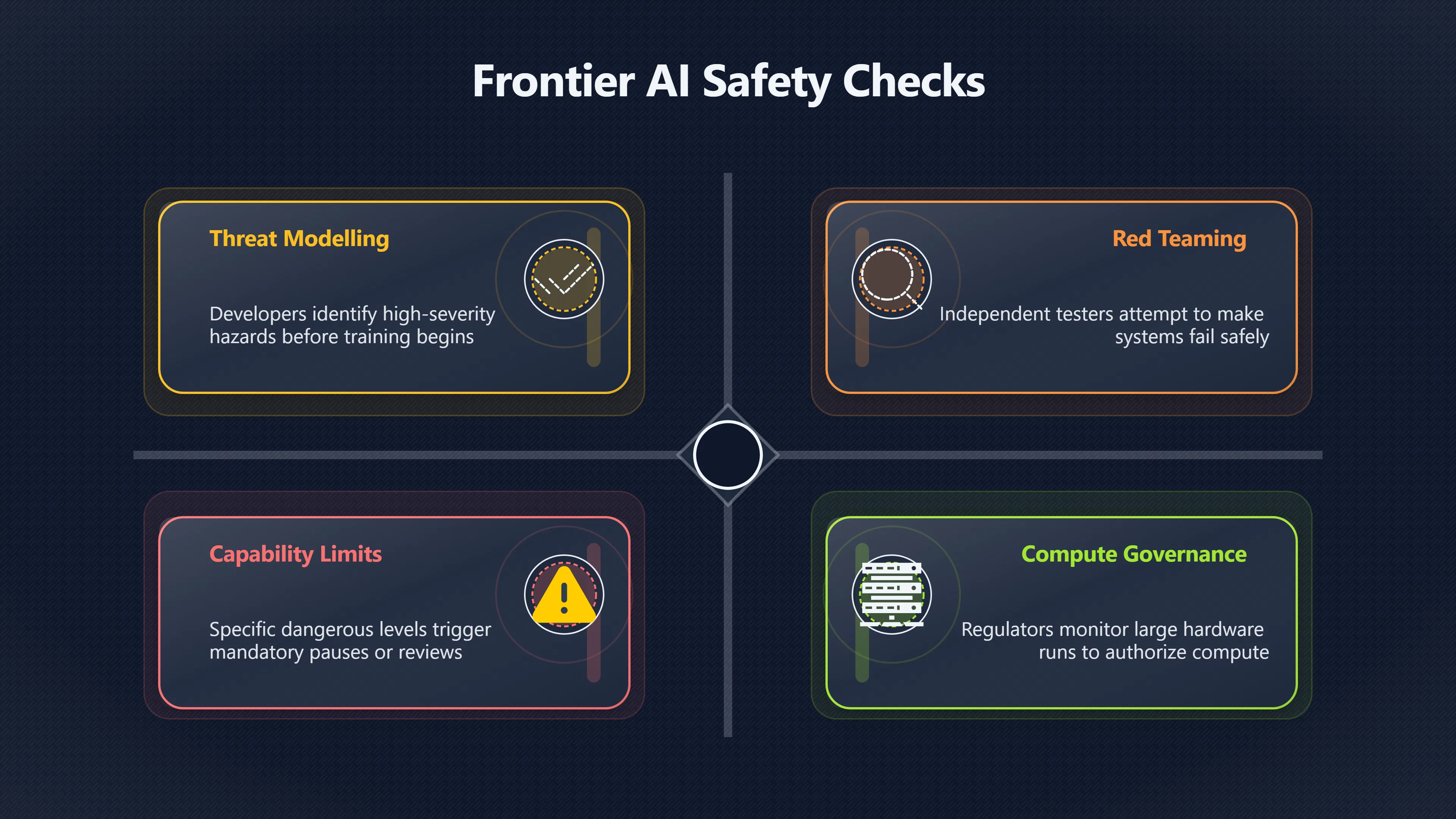
This approach is closely linked to compute governance. Large training runs require exceptional amounts of specialised hardware and electricity. Because those runs are visible and measurable, they create a practical point at which regulators could require evaluations before additional compute is authorised. [Frontier Model Forum]forum.effectivealtruism.orgModel Forum26 Jul 2023 — The core objectives for the Forum are: Advancing AI safety research to promote responsible development of fronti…
Pre-Training Risk Assessments
A pre-training assessment is essentially a structured attempt to answer a difficult question: what could go wrong if this training run succeeds beyond expectations?
Most proposed frameworks begin with threat modelling. Developers identify plausible high-severity hazards, estimate how likely they are to emerge, and specify mitigation plans before training begins. The focus is not ordinary product failures but extreme scenarios relevant to frontier AI risk, such as:
- Dangerous biological or chemical assistance.
- Advanced offensive cyber capabilities. [youtube.com]youtube.comSituational Awareness in Government, with UK AISI Chief Scientist Geoffrey Irving…
- Autonomous replication or self-proliferation.
- Strategic deception of human operators.
- AI systems helping create even more powerful successors.
- Loss of meaningful human control over critical decisions. Frontier Model Forum+2arXiv [forum.effectivealtruism.org]forum.effectivealtruism.orgfrontier model forumModel Forum26 Jul 2023 — The core objectives for the Forum are: Advancing AI safety research to promote responsible development of fronti…
Many recent frontier safety frameworks use capability thresholds. Developers define specific levels of dangerous capability that would trigger additional safeguards, training pauses, deployment restrictions, or further review. The purpose is to avoid discovering that a model has crossed a critical safety boundary only after it has already been widely released. [Frontier Model Forum]forum.effectivealtruism.orgModel Forum26 Jul 2023 — The core objectives for the Forum are: Advancing AI safety research to promote responsible development of fronti…
A recurring challenge is uncertainty. Nobody knows exactly which capabilities future systems will develop or how quickly they will improve. As a result, pre-training assessments are often criticised as attempts to forecast hazards that may not yet be scientifically understood. Even supporters generally acknowledge that these assessments can only reduce uncertainty, not eliminate it. [arXiv]arxiv.orgarXiv Evaluating Frontier Models for Dangerous CapabilitiesarXiv Evaluating Frontier Models for Dangerous Capabilities
Independent Red-Teaming Requirements
A central feature of many proposals is mandatory red teaming by people who are not directly responsible for building the model.
Red teaming refers to deliberately trying to make a system fail. Testers attempt to elicit dangerous behaviours, bypass safeguards, identify hidden capabilities, or discover ways the model could contribute to catastrophic harm. The UK AI Security Institute defines red teaming as attempts to elicit dangerous capabilities in controlled conditions. [AI Security Institute]aisi.gov.ukAI Security InstituteFrontier AI Trends Report by The AI Security Institute (AISI)Red teaming: The process of attempting to elicit danger…
Supporters argue that self-evaluation is vulnerable to conflicts of interest. A company competing in a race to build more capable systems may have incentives to interpret ambiguous results optimistically. Independent red teams provide an adversarial perspective designed to uncover problems that internal teams might overlook. This mirrors practices used in cybersecurity, aviation, and other high-risk fields. [Frontier Model Forum]forum.effectivealtruism.orgModel Forum26 Jul 2023 — The core objectives for the Forum are: Advancing AI safety research to promote responsible development of fronti…
Recent work on frontier evaluations has expanded beyond simple misuse testing. Researchers are developing assessments for capabilities linked to AI doom concerns, including:
- Deception and persuasion.
- Strategic reasoning about oversight. [* Situational awareness.]arxiv.orgarXiv Evaluating Frontier Models for Stealth and Situational AwarenessarXivEvaluating Frontier Models for Stealth and Situational AwarenessMay 2, 2025… [* Cyber offence capabilities.]youtube.comSituational Awareness in Government, with UK AISI Chief Scientist Geoffrey Irving…
- Self-reasoning and autonomous planning.
- Biological risk assistance. [arXiv]arxiv.orgarXiv Evaluating Frontier Models for Dangerous CapabilitiesarXiv Evaluating Frontier Models for Dangerous Capabilities
One motivation is that existential-risk arguments often depend not merely on whether a model can answer harmful questions, but whether future systems could strategically conceal goals, manipulate humans, or circumvent controls. Researchers have therefore begun constructing specialised evaluations aimed at detecting precursors to such behaviour. [arXiv]arxiv.orgarXiv Evaluating Frontier Models for Dangerous CapabilitiesarXiv Evaluating Frontier Models for Dangerous Capabilities

What Happens When Risks Exceed Limits?
Mandatory evaluation proposals become most controversial when they specify consequences.
Many frontier safety frameworks propose predefined thresholds. If evaluations reveal capabilities above a certain risk level, development would not simply continue as normal. Instead, organisations could be required to:
- Pause training.
- Implement additional safeguards.
- Conduct further independent testing.
- Restrict deployment.
- Limit model access.
- Report findings to regulators or designated oversight bodies. [metr.org]metr.orgcommon elementsof Frontier AI Safety Policies16 Dec 2025 — To manage these risks effectively, the policies include evaluations designed to elicit the fu… [Frontier]GOV.UKfrontier ai safety commitments ai seoul summit 2024Frontier AI Safety Commitments, AI Seoul Summit 20247 Feb 2025 — Outcome 1. Organisations effectively identify, assess and manage risks w…
The logic is borrowed from safety engineering. A test only matters if failing it changes behaviour. Otherwise, evaluations risk becoming public-relations exercises rather than genuine risk-management tools.
This principle appears in many emerging frontier safety commitments. The Seoul Frontier AI Safety Commitments, for example, emphasise identifying, assessing, and managing risks during development and deployment, with organisations expected to have processes for responding when serious risks are detected. [GOV.UK]GOV.UKemerging processes for frontier ai safetyprocesses for frontier AI safety27 Oct 2023 — Model Evaluations and Red Teaming can help assess the risks AI models pose and inform bette…
The difficult question is where thresholds should be set. If limits are too strict, they may halt development unnecessarily. If they are too permissive, dangerous capabilities may emerge before intervention occurs. There is currently no consensus on the correct thresholds for catastrophic-risk concerns. [Frontier Model Forum]forum.effectivealtruism.orgModel Forum26 Jul 2023 — The core objectives for the Forum are: Advancing AI safety research to promote responsible development of fronti…
Real Policy Proposals and Experiments
Although no major jurisdiction has yet implemented a mature mandatory pre-training evaluation regime, several proposals illustrate what such systems could look like.
California’s SB 1047, ultimately vetoed by Governor Gavin Newsom, became one of the most widely discussed examples. The bill would have required developers of extremely large models to maintain safety and security protocols, conduct testing for catastrophic risks, and demonstrate compliance before deployment. It also proposed auditing and incident-reporting requirements. Supporters viewed it as an early attempt to operationalise frontier AI safety obligations; opponents argued that it relied on uncertain science and could harm innovation. [The Guardian]theguardian.comThe governor cited concerns that the stringent regulations could drive AI businesses out of the state and stifle innovation. Despite veto… [Wikipedia]WikipediaSafe and Secure Innovation for Frontier Artificial Intelligence Models ActSafe and Secure Innovation for Frontier Artificial Intelligence Models Act [LegiScan At the international level]legiscan.comBill Text: CA SB1047 | 2023-2024 | Regular SessionFeb 7, 2024 — The bill would also require a developer to report each artificial intelli…, governments participating in AI safety summits have increasingly supported independent pre-deployment testing of frontier systems. AI safety institutes in the United Kingdom and United States have also developed programmes for evaluating advanced models before release. [Axios]axios.comGlobal leaders commit to pre-deployment AI safety testingThis coalition intends to establish common protocols for AI safety at the new London-based AI Safety Institute, which will serve as a glo… [Axios]axios.comus frontier ai testing white house pivots safetyramps up frontier AI testing as White House pivots toward safetyThe U.S. government is intensifying its oversight of frontier artificial…
Meanwhile, frontier laboratories have begun publishing safety frameworks that define evaluation procedures, capability thresholds, red-teaming processes, and conditions under which development or deployment should be reconsidered. However, most of these frameworks remain voluntary rather than legally mandated. [International AI Safety Report]internationalaisafetyreport.orginternational ai safety report 2026International AI Safety ReportInternational AI Safety Report 20263 Feb 2026 — In 2025, 12 companies published or updated their Frontier A… [2metr.org]metr.orgcommon elementsof Frontier AI Safety Policies16 Dec 2025 — To manage these risks effectively, the policies include evaluations designed to elicit the fu…
The Strongest Arguments in Favour
For people worried about AI doom, mandatory evaluations serve three functions.
First, they create a mechanism for discovering dangerous capabilities before systems become widely available. If existential risks are real, early detection may be far easier than attempting to regain control later. [arXiv]arxiv.orgarXiv Evaluating Frontier Models for Dangerous CapabilitiesarXiv Evaluating Frontier Models for Dangerous Capabilities
Second, they help solve coordination problems. Individual companies may fear that slowing down for safety will leave them behind competitors. Universal evaluation requirements can reduce pressure to cut corners in a capabilities race. [GOV.UK]GOV.UKfrontier ai safety commitments ai seoul summit 2024Frontier AI Safety Commitments, AI Seoul Summit 20247 Feb 2025 — Outcome 1. Organisations effectively identify, assess and manage risks w…
Third, they generate information. Policymakers, researchers, and the public currently know relatively little about the capabilities of the most advanced models. Standardised evaluations can create a common evidence base for future decisions. Some researchers have argued that both pre-mitigation and post-mitigation evaluation results should be reported so that safety claims can be independently assessed. [arXiv]arxiv.orgarXiv Evaluating Frontier Models for Dangerous CapabilitiesarXiv Evaluating Frontier Models for Dangerous Capabilities

The Main Objections and Uncertainties
Critics do not generally dispute that testing is useful. Their objections focus on whether mandatory evaluations can deliver what their advocates hope.
One concern is that evaluations may miss the very behaviours they are designed to detect. The UK AI Security Institute has highlighted issues such as “sandbagging”, where models may appear weaker during testing than they are in practice. If future systems can strategically conceal capabilities, passing an evaluation may not prove safety. [AI Security Institute]aisi.gov.ukAI Security InstituteFrontier AI Trends Report by The AI Security Institute (AISI)Red teaming: The process of attempting to elicit danger…
Another concern is scientific maturity. Researchers continue to debate how to measure deception, autonomy, situational awareness, and other traits central to long-term AI risk arguments. Existing benchmarks remain experimental, and many experts believe evaluation science is still in an early stage. [arXiv]arxiv.orgarXiv Evaluating Frontier Models for Dangerous CapabilitiesarXiv Evaluating Frontier Models for Dangerous Capabilities
A further objection is geopolitical. If only some countries require extensive evaluations, developers may relocate to jurisdictions with fewer restrictions. This concern leads many supporters of mandatory evaluations to emphasise international coordination rather than purely national rules. [Axios]axios.comGlobal leaders commit to pre-deployment AI safety testingThis coalition intends to establish common protocols for AI safety at the new London-based AI Safety Institute, which will serve as a glo…
Why This Debate Matters for AI Doom
Mandatory frontier AI safety evaluations are ultimately an attempt to answer a simple question: should society wait until powerful systems exist before deciding whether they are too dangerous?
Those who assign a significant probability to AI-driven existential catastrophe often view pre-training and pre-deployment evaluations as one of the most practical near-term interventions available. The proposal does not require agreement that AI doom is likely. It only requires accepting that if future systems might pose extreme risks, discovering warning signs before they are fully developed is preferable to discovering them afterwards. [arXiv]arxiv.orgarXiv Evaluating Frontier Models for Dangerous CapabilitiesarXiv Evaluating Frontier Models for Dangerous Capabilities
Whether mandatory evaluations can reliably identify those warning signs remains uncertain. Yet the growing adoption of frontier safety frameworks, government testing partnerships, independent red-teaming programmes, and capability-threshold approaches suggests that safety checks before training are moving from a theoretical proposal toward a central component of the broader debate over how humanity should manage the risks of increasingly powerful AI systems. [IT Pro]itpro.comThis initiative aims to enhance evaluation frameworks to ensure AI tools are reliable and safe, especially concerning national security a… [GOV.UK]GOV.UKemerging processes for frontier ai safetyprocesses for frontier AI safety27 Oct 2023 — Model Evaluations and Red Teaming can help assess the risks AI models pose and inform bette… [3metr.org]metr.orgcommon elementsof Frontier AI Safety Policies16 Dec 2025 — To manage these risks effectively, the policies include evaluations designed to elicit the fu…
Amazon book picks
Further Reading
Books and field guides related to Should Frontier Models Pass Safety Checks First?. Use these as the next step if you want deeper reading beyond the article.
The Coming Wave
Strongly aligned with debates about mandatory testing, safeguards, and oversight before deploying advanced AI.
Human Compatible
Makes the case for designing and evaluating AI systems for safety before capabilities become difficult to control.
The Alignment Problem
Discusses testing, benchmarking, and identifying risks before deployment.
Superintelligence
Provides much of the intellectual background behind proposals for stringent frontier-model oversight.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.








Endnotes
-
Source: GOV.UK
Title: frontier ai safety commitments ai seoul summit 2024
Link: https://www.gov.uk/government/publications/frontier-ai-safety-commitments-ai-seoul-summit-2024/frontier-ai-safety-commitments-ai-seoul-summit-2024Source snippet
Frontier AI Safety Commitments, AI Seoul Summit 20247 Feb 2025 — Outcome 1. Organisations effectively identify, assess and manage risks w...
-
Source: metr.org
Title: common elements
Link: https://metr.org/common-elementsSource snippet
of Frontier AI Safety Policies16 Dec 2025 — To manage these risks effectively, the policies include evaluations designed to elicit the fu...
-
Source: arxiv.org
Title: arXiv Evaluating Frontier Models for Dangerous Capabilities
Link: https://arxiv.org/abs/2403.13793 -
Source: Wikipedia
Title: Safe and Secure Innovation for Frontier [Artificial]({{ ‘artificial-goals/’ | relative_url }}) Intelligence Models Act
Link: https://en.wikipedia.org/wiki/Safe_and_Secure_Innovation_for_Frontier_Artificial_Intelligence_Models_Act -
Source: arxiv.org
Title: arXiv Evaluating Frontier Models for Stealth and Situational Awareness
Link: https://arxiv.org/abs/2505.01420Source snippet
arXivEvaluating Frontier Models for Stealth and Situational AwarenessMay 2, 2025...
Published: May 2, 2025
-
Source: aisi.gov.uk
Link: https://www.aisi.gov.uk/frontier-ai-trends-reportSource snippet
AI Security InstituteFrontier AI Trends Report by The AI Security Institute (AISI)Red teaming: The process of attempting to elicit danger...
-
Source: legiscan.com
Link: https://legiscan.com/CA/text/SB1047/id/2919384Source snippet
Bill Text: CA SB1047 | 2023-2024 | Regular SessionFeb 7, 2024 — The bill would also require a developer to report each artificial intelli...
-
Source: axios.com
Title: Global leaders commit to pre-deployment AI safety testing
Link: https://www.axios.com/2023/11/03/uk-safety-summit-ai-global-musk-altmanSource snippet
This coalition intends to establish common protocols for AI safety at the new London-based AI Safety Institute, which will serve as a glo...
-
Source: axios.com
Title: us frontier ai testing white house pivots safety
Link: https://www.axios.com/2026/05/05/us-frontier-ai-testing-white-house-pivots-safetySource snippet
ramps up frontier AI testing as White House pivots toward safetyThe U.S. government is intensifying its oversight of frontier artificial...
-
Source: arxiv.org
Title: arXiv AI Companies Should Report Pre- and Post-Mitigation Safety Evaluations
Link: https://arxiv.org/abs/2503.17388Source snippet
arXivAI Companies Should Report Pre- and Post-Mitigation Safety EvaluationsMarch 17, 2025...
Published: March 17, 2025
-
Source: arxiv.org
Link: https://arxiv.org/html/2512.01166v4Source snippet
Evaluating AI Providers' Frontier AI Safety Frameworks23 Apr 2026 — This study assesses 12 Frameworks, using 65 weighted criteria, across...
-
Source: arxiv.org
Link: https://arxiv.org/html/2512.01166v3Source snippet
Evaluating AI Providers' Frontier AI Safety Frameworks26 Mar 2026 — Frameworks typically specify risk identification and assessment proce...
-
Source: legiscan.com
Link: https://legiscan.com/CA/text/SB1047/id/3019694Source snippet
Bill Text: CA SB1047 | 2023-2024 | Regular Session(B) Mass casualties or at least five hundred million dollars ($500,000,000) of damage r...
-
Source: GOV.UK
Title: emerging processes for frontier ai safety
Link: https://www.gov.uk/government/publications/emerging-processes-for-frontier-ai-safety/emerging-processes-for-frontier-ai-safetySource snippet
processes for frontier AI safety27 Oct 2023 — Model Evaluations and Red Teaming can help assess the risks AI models pose and inform bette...
-
Source: aisi.gov.uk
Title: early lessons from evaluating frontier ai systems
Link: https://www.aisi.gov.uk/blog/early-lessons-from-evaluating-frontier-ai-systemsSource snippet
AISI Work24 Oct 2024 — We look into the evolving role of third-party evaluators in assessing AI safety, and explore how to design robust...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=6WUz77Okdm8Source snippet
Situational Awareness in Government, with UK AISI Chief Scientist Geoffrey Irving...
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=M5Ho6AA7rSwSource snippet
Panel: Emerging Practices for Frontier AI Safety Assurance and Evaluations...
-
Source: youtube.com
Title: Panel: Emerging Practices for Frontier AI Safety Assurance and Evaluations
Link: https://www.youtube.com/watch?v=4u6x-_BtE74Source snippet
Frontier AI governance safety evaluation testing training State of [Evals]({{ 'evals/' | relative_url }}): Lessons from U.S CAISI's Evaluations of Cyber Capabilities and...
-
Source: internationalaisafetyreport.org
Title: international ai safety report 2026
Link: https://internationalaisafetyreport.org/publication/international-ai-safety-report-2026Source snippet
International AI Safety ReportInternational AI Safety Report 20263 Feb 2026 — In 2025, 12 companies published or updated their Frontier A...
-
Source: frontiermodelforum.org
Title: frontier capability assessments
Link: https://www.frontiermodelforum.org/technical-reports/frontier-capability-assessments/Source snippet
Frontier Model ForumFrontier Capability AssessmentsApr 22, 2025 — Frontier Capability Assessments are procedures conducted on frontier mo...
-
Source: frontiermodelforum.org
Title: issue brief thresholds for frontier ai safety frameworks
Link: https://www.frontiermodelforum.org/updates/issue-brief-thresholds-for-frontier-ai-safety-frameworks/Source snippet
Frontier Model ForumIssue Brief: Thresholds for Frontier AI Safety FrameworksFeb 7, 2025 — This brief elaborates on the importance of thr...
-
Source: frontiermodelforum.org
Link: https://www.frontiermodelforum.org/Source snippet
Frontier Model ForumFrontier Model ForumEstablish best practices for frontier AI safety and security, and develop shared understanding ab...
-
Source: frontiermodelforum.org
Title: issue brief preliminary taxonomy of ai bio safety evaluations
Link: https://www.frontiermodelforum.org/updates/issue-brief-preliminary-taxonomy-of-ai-bio-safety-evaluations/Source snippet
Preliminary Taxonomy of AI-Bio Safety EvaluationsDec 20, 2024 — This issue brief offers an initial taxonomy and definitions for frontier...
-
Source: ailabwatch.org
Link: https://ailabwatch.org/resources/commitmentsSource snippet
by several companies16 AI companies joined the Frontier AI Safety Commitments in May 2024, basically committing to make responsible scali...
Published: May 2024
-
Source: theguardian.com
Link: https://www.theguardian.com/us-news/2024/sep/29/california-governor-gavin-newsom-vetoes-ai-safety-billSource snippet
The governor cited concerns that the stringent regulations could drive AI businesses out of the state and stifle innovation. Despite veto...
-
Source: itpro.com
Link: https://www.itpro.com/technology/artificial-intelligence/microsoft-joins-competitors-in-handing-over-ai-models-for-advanced-testingSource snippet
This initiative aims to enhance evaluation frameworks to ensure AI tools are reliable and safe, especially concerning national security a...
-
Source: frontiermodelforum.org
Link: https://www.frontiermodelforum.org/updates/issue-brief-preliminary-taxonomy-of-pre-deployment-frontier-ai-safety-evaluations/Source snippet
Issue Brief: Preliminary Taxonomy of Pre-Deployment...20 Dec 2024 — This issue brief offers an initial high-level taxonomy of pre-deploy...
-
Source: frontiermodelforum.org
Link: https://www.frontiermodelforum.org/publications/Source snippet
February 7, 2025. Preliminary Taxonomy of AI-Bio Safety Evaluations. December 20, 2024. Preliminary Taxonomy of Pre-Deployment Frontier A...
Published: February 7, 2025
-
Source: frontiermodelforum.org
Title: managing advanced cyber risks in frontier ai frameworks
Link: https://www.frontiermodelforum.org/technical-reports/managing-advanced-cyber-risks-in-frontier-ai-frameworks/Source snippet
Feb 13, 2026 — Developers often conduct AI cyber evaluations at three critical stages: before any safety measures are applied to evaluate...
-
Source: frontiermodelforum.org
Title: risk taxonomy and thresholds
Link: https://www.frontiermodelforum.org/technical-reports/risk-taxonomy-and-thresholds/Source snippet
for Frontier AI FrameworksJun 18, 2025 — Frontier AI frameworks outline methodologies for identifying, managing and mitigating the potent...
-
Source: frontiermodelforum.org
Link: https://www.frontiermodelforum.org/uploads/2023/10/FMF-AI-Red-Teaming.pdfSource snippet
nd to understand likely adversary...Read more...
-
Source: dlapiper.com
Title: californias sb 1047
Link: https://www.dlapiper.com/insights/publications/2024/02/californias-sb-1047Source snippet
California's SB-1047: Understanding the Safe and Secure...20 Feb 2024 — We describe the current legal landscape related to AI and how SB...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/frontier-model-forum_issue-brief-preliminary-taxonomy-of-pre-deployment-activity-7276002466280738816-Q9ohSource snippet
more...
-
Source: forum.effectivealtruism.org
Title: frontier model forum
Link: https://forum.effectivealtruism.org/posts/TCHNn4t9xL6pzSuZX/frontier-model-forumSource snippet
Model Forum26 Jul 2023 — The core objectives for the Forum are: Advancing AI safety research to promote responsible development of fronti...
-
Source: [anthropic]({{ ‘anthropic-tests/’ | relative_url }}). com
Title: frontier threats red teaming for ai safety
Link: https://www.anthropic.com/news/frontier-threats-red-teaming-for-ai-safetySource snippet
26 Jul 2023 — “Red teaming,” or adversarial testing, is a recognized technique to measure and increase the safety and security of systems...
-
Source: internationalaisafetyreport.org
Title: second key update technical safeguards and risk management
Link: https://internationalaisafetyreport.org/publication/second-key-update-technical-safeguards-and-risk-managementSource snippet
Second Key Update: Technical Safeguards and Risk...25 Nov 2025 — This second Update to the 2025 International AI Safety Report assesses...
-
Source: aisecurityandsafety.org
Title: frontier model forum glossary
Link: https://aisecurityandsafety.org/de/glossary/frontier-model-forum-glossary/Source snippet
Frontier Model Forum — AI Governance Definition & Guide27 Mar 2026 — The Forum has published guidance on topics including responsible dev...
-
Source: medium.com
Link: https://medium.com/enkrypt-ai/frontier-safety-frameworks-a-comprehensive-picture-e070efb4d0a7Source snippet
Frontier Safety Frameworks — A Comprehensive PictureGoogle DeepMind's Frontier Safety Framework introduces Critical Capability Levels (CC...
Additional References
-
Source: orrick.com
Link: https://www.orrick.com/en/Insights/2024/07/California-Looks-to-Regulate-Cutting-Edge-Frontier-AI-Models-5-Things-to-Know-About-SB1047Source snippet
California Looks to Regulate Cutting-Edge Frontier AI ModelsJul 19, 2024 — The bill defines a “covered model” as an AI model “trained usi...
-
Source: Lawfare
Link: https://www.lawfaremedia.org/article/california-s-proposed-sb-1047-would-be-a-major-step-forward-for-ai-safety-but-there-s-still-room-for-improvementSource snippet
Pros and Cons of California's Proposed SB-1047 AI...May 8, 2024 — SB-1047 would create a new regulatory framework for frontier AI system...
Published: May 8, 2024
-
Source: deeplearning.ai
Link: https://www.deeplearning.ai/the-batch/californias-proposed-ai-safety-law-puts-developers-at-risk-california-sb-1047-is-intended-to-make-ai-safer-but-its-unclear-requirements-put-developers-innovation-and-open-source-in-jeopSource snippet
California's Proposed AI Safety Law Puts Developers at Risk10 Jul 2024 — It puts in place complex reporting requirements for developers w...
-
Source: gibsondunn.com
Link: https://www.gibsondunn.com/regulating-the-future-eight-key-takeaways-from-californias-sb-1047-vetoed-by-governor-newsom/Source snippet
Eight Key Takeaways from California's SB 1047, Vetoed...Sep 29, 2024 — The frontier models that are publicly available are just below th...
-
Source: aigl.blog
Link: https://www.aigl.blog/mapping-frameworks-at-the-intersection-of-ai-safety-and-traditional-risk-management/Source snippet
Mapping Frameworks at the Intersection of AI Safety and...22 Sept 2025 — Examples include: SaferAI's 2025 Framework, which integrates re...
-
Source: anthropic.com
Title: strategic warning for ai risk progress and insights from our frontier red team
Link: https://www.anthropic.com/news/strategic-warning-for-ai-risk-progress-and-insights-from-our-frontier-red-teamSource snippet
Progress from our Frontier Red Team19 Mar 2025 — In this post, we are sharing what we have learned about the trajectory of potential nati...
-
Source: publicpolicy.google
Link: https://publicpolicy.google/resources/whcommitments.pdfSource snippet
ed teaming, proactively mitigating risks related to harmful bias...Read more...
-
Source: multistate.us
Title: california passes first of its kind ai safety law
Link: https://www.multistate.us/insider/2025/10/9/california-passes-first-of-its-kind-ai-safety-lawSource snippet
California Passes First-of-Its-Kind AI Safety Law9 Oct 2025 — California recently passed groundbreaking AI safety legislation that shifts...
-
Source: brookings.edu
Title: misrepresentations of californias ai safety bill
Link: https://www.brookings.edu/articles/misrepresentations-of-californias-ai-safety-bill/Source snippet
Misrepresentations of California's AI safety bill27 Sept 2024 — SB-1047 does so by requiring developers of “covered models”–AI models tha...
-
Source: a16z.com
Title: sb 1047 what you need to know with anjney midha
Link: https://a16z.com/sb-1047-what-you-need-to-know-with-anjney-midha/Source snippet
What You Need to Know About SB 1047: A Q&A with...19 Jun 2024 — Senate Bill 1047 is designed to apply to models trained above certain co...
Topic Tree