Within Weak evidence
How AlphaZero's Self Play Is Restricted by Game Rules
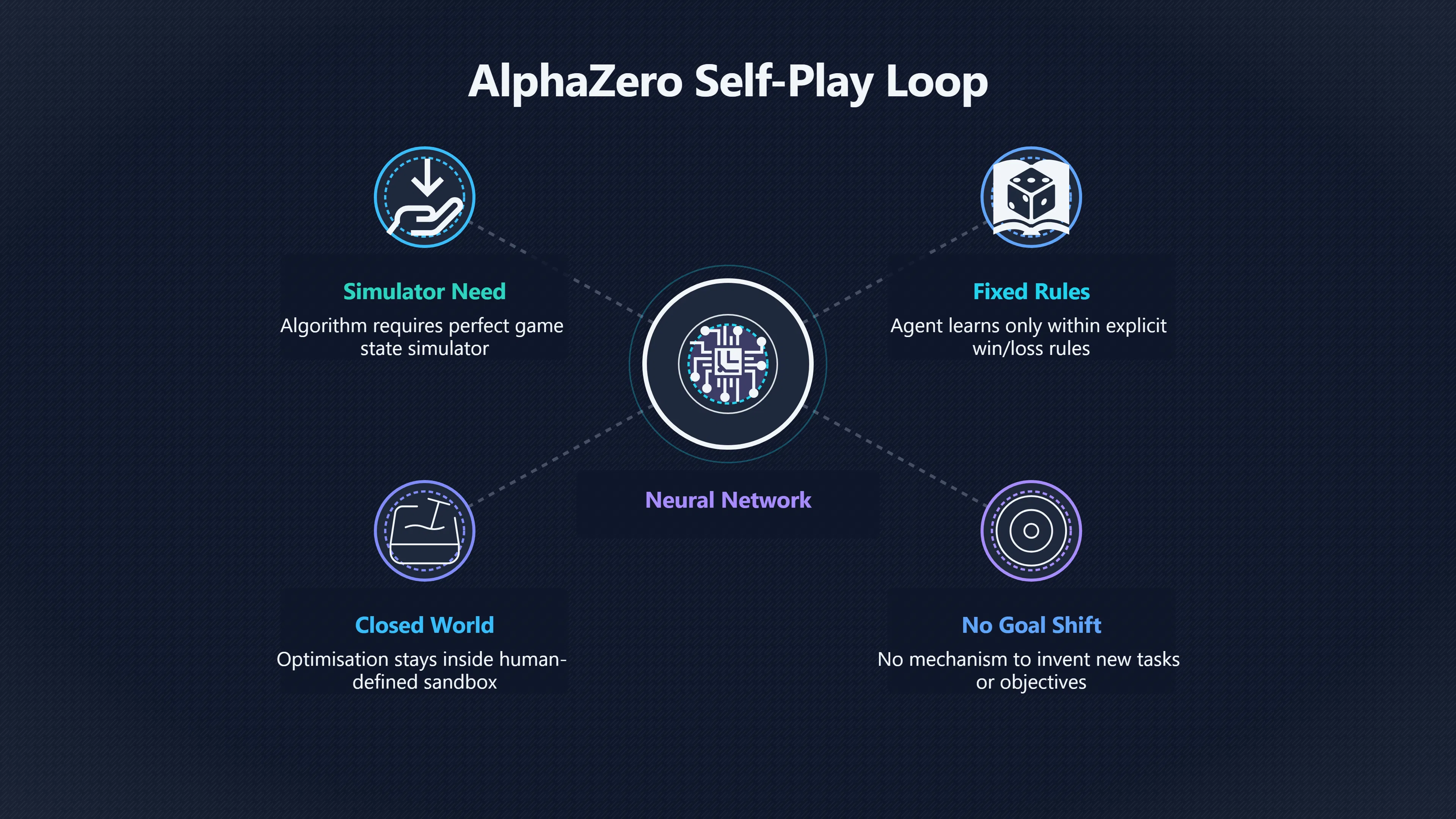
AlphaZero demonstrates rapid learning in games but remains confined to predefined rules and objectives without human-independent exploration.
On this page
- Overview of AlphaZero self play methodology
- Boundaries imposed by human defined rules and objectives
- Implications for recursive AI improvement debates
Page outline Jump by section
Introduction
AlphaZero’s self‑play breakthrough often gets cited in debates about autonomous machine intelligence, recursive self‑improvement, and existential risk from AI. In games such as chess, Go and shogi, the DeepMind system learned from scratch by repeatedly playing against itself until it reached world‑class strength with no human data beyond the rules of the game. [AI Wiki]aiwiki.aiAI Wiki Alpha Zero | AI WikiAI WikiAlphaZero | AI WikiApril 26, 2026… But that impressive self‑play loop has important limits: it operates inside narrow, human‑defined environments, without independent exploration, goal‑setting, or expansion beyond those environments. This matters because some arguments about AI “take‑off” assume that self‑improvement abilities like AlphaZero’s could generalise across open‑ended, real‑world tasks; the evidence here shows why those analogies are weak.

How AlphaZero’s Self‑Play Works and Why It’s Constrained
AlphaZero is a reinforcement‑learning agent that combines a neural network with Monte Carlo Tree Search (MCTS). Starting with no domain expertise aside from the formal rules, it plays millions of simulated games against copies of itself. Outcomes of these self‑plays generate training data that update the network, improving future play. [AI Wiki]aiwiki.aiAI Wiki Alpha Zero | AI WikiAI WikiAlphaZero | AI WikiApril 26, 2026… This feedback loop lets AlphaZero ascend to superhuman play in specific rule‑bound domains.
But the scope of that loop is tightly bounded by design:
- Fixed rules and reward structure: AlphaZero only learns within well‑defined, deterministic games where win/loss outcomes are clear and reward functions are explicit. There is no mechanism for changing objectives or inventing new tasks beyond what humans specify. [informatica.si]informatica.siAlpha Zero – What’s Missing? | InformaticaAlphaZero – What’s Missing? | InformaticaMarch 26, 2018…
- Complete simulator requirement: The algorithm needs a perfect simulator of the game state to use MCTS effectively. This limits it to perfect‑information, deterministic environments; situations with hidden information, stochasticity or continuous action spaces are outside its native design. [AI Wiki]aiwiki.aiAI Wiki Alpha Zero | AI WikiAI WikiAlphaZero | AI WikiApril 26, 2026…
- Lack of autonomous exploration outside game tree: Research on its training dynamics shows AlphaZero’s self‑play starts matches from initial game states and samples only limited trajectories through the game tree. It does not systematically explore all reachable states, especially deeper or unusual ones, reflecting that its “curiosity” is constrained by the rules and its own policy search biases. [ResearchGate]researchgate.netSource details in endnotes.
These constraints mean AlphaZero optimises within a closed world rather than discovering or creating new goals, environments, or domains on its own.
Why These Limits Matter for Recursive AI Improvement Debates
In discussions of AI doom and recursive self‑improvement, a central claim is that an AI could bootstrap itself to ever greater intelligence without ongoing human intervention. AlphaZero’s self‑play loop superficially resembles a positive feedback mechanism — the system improves by generating its own data — but its domain constraints make it a poor model for open‑ended self‑enhancement:
- Human‑defined environment and objectives: Unlike a hypothetical recursive agent that might expand its operational domain or invent its own objectives, AlphaZero’s induction is bound to the single, fixed optimisation problem of playing a given game. It has no built‑in drive to extend beyond what was framed by its designers.
- No independent goal formulation: The system does not learn why it is optimising; it simply maximises expected game outcomes as defined by the rules. There is no internal mechanism for redefining what “better” means outside the game context.
- Limited state exploration: Empirical studies suggest AlphaZero’s training explores limited regions of the game state space and fails on tasks requiring human‑like planning or puzzle solving outside the straight win‑rate optimisation. [OpenReview]openreview.netOpen Review Limitations in Planning Ability in Alpha Zero | Open ReviewOpenReviewLimitations in Planning Ability in AlphaZero | OpenReviewOctober 10, 2024…
Taken together, these points show why many researchers caution against equating AlphaZero’s self‑play success with evidence of autonomous, recursive intelligence growth. Its achievements are bound to narrow, high‑compute scenarios where the optimisation problem is entirely specified.

Broader Context: Beyond Games
It’s worth noting that subsequent research has aimed to generalise the ideas behind AlphaZero — for example, MuZero learns a model of the environment itself, reducing reliance on pre‑specified rules. [AI Wiki]aiwiki.aiAI Wiki Alpha Zero | AI WikiAI WikiAlphaZero | AI WikiApril 26, 2026… But even these advances remain in experimental domains and stop short of unconstrained self‑directed improvement across arbitrary tasks. Meanwhile, theoretical and empirical work (e.g., on “impartial games” or planning puzzles) highlights concrete limits to AlphaZero‑style algorithms in broader problem classes. [DeepAI]deepai.orgimpartial games a challenge for reinforcement learningDeepAIImpartial Games: A Challenge for Reinforcement Learning | DeepAIMay 25, 2022…
For people concerned about AI risk, the upshot is clear: while AlphaZero is a striking demonstration of machine learning capability within a sandbox, the mechanisms that make it work do not by themselves generalise to the kind of open‑ended recursive self‑improvement imagined in many AI doom scenarios. This doesn’t rule out future systems that might combine self‑play with goal discovery or meta‑learning, but it does weaken claims that AlphaZero‑like loops are direct precursors to rapid capability take‑off.
Key Takeaways
- AlphaZero’s self‑play is powerful in structured, rule‑bound environments but cannot extend itself beyond the game domains defined by humans. [informatica.si]informatica.siAlpha Zero – What’s Missing?| Bratko | InformaticaAbout The Author Ivan Bratko University of Ljubljana, Faculty of Computer and Information Science Slovenia Support…
- It requires a complete simulator and predefined rewards, meaning it lacks autonomy to explore or redefine tasks. [AI Wiki]aiwiki.aiAI Wiki Alpha Zero | AI WikiAI WikiAlphaZero | AI WikiApril 26, 2026…
- Empirical research shows it doesn’t inherently grasp broad strategic reasoning beyond winning games, underscoring the practical limits of self‑play loops as models for unrestricted recursive improvement. [OpenReview]openreview.netOpen Review Limitations in Planning Ability in Alpha Zero | Open ReviewOpenReviewLimitations in Planning Ability in AlphaZero | OpenReviewOctober 10, 2024…
These constraints help clarify why achievements like AlphaZero, though impressive, are seen as weak evidence for the kind of autonomous, recursive intelligence often feared in AI doom narratives.

Amazon book picks
Further Reading
Books and field guides related to How AlphaZero's Self Play Is Restricted by Game Rules. Use these as the next step if you want deeper reading beyond the article.
Reinforcement Learning, second edition
Provides the foundations needed to understand AlphaZero, self-play, reward functions, and the limits imposed by fixed environments.
Deep Reinforcement Learning Hands-On
Covers modern deep reinforcement learning approaches and discusses AlphaGo Zero-related methods.
Human Compatible
Addresses AI capability, objectives, and why narrow optimization systems differ from open-ended intelligence.
Artificial Intelligence
Rating: 4.5/5 from 10 Google Books ratings
Provides technical grounding for self-play, AutoML and AI capabilities.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.








Endnotes
-
Source: informatica.si
Title: Alpha Zero – What’s Missing? | Informatica
Link: https://www.informatica.si/index.php/informatica/article/view/2226Source snippet
AlphaZero – What’s Missing? | InformaticaMarch 26, 2018...
Published: March 26, 2018
-
Source: researchgate.net
Link: https://www.researchgate.net/publication/368829510_Targeted_Search_Control_in_AlphaZero_for_Effective_Policy_Improvement -
Source: openreview.net
Title: Open Review Limitations in Planning Ability in Alpha Zero | Open Review
Link: https://openreview.net/forum?id=ZAbYb4jDJtSource snippet
OpenReviewLimitations in Planning Ability in AlphaZero | OpenReviewOctober 10, 2024...
Published: October 10, 2024
-
Source: deepai.org
Title: impartial games a challenge for reinforcement learning
Link: https://deepai.org/publication/impartial-games-a-challenge-for-reinforcement-learningSource snippet
DeepAIImpartial Games: A Challenge for Reinforcement Learning | DeepAIMay 25, 2022...
Published: May 25, 2022
-
Source: informatica.si
Title: Alpha Zero – What’s Missing?
Link: https://www.informatica.si/index.php/informatica/article/view/2226%3E/0Source snippet
| Bratko | InformaticaAbout The Author Ivan Bratko University of Ljubljana, Faculty of Computer and Information Science Slovenia Support...
-
Source: aiwiki.ai
Title: AI Wiki Alpha Zero | AI Wiki
Link: https://aiwiki.ai/wiki/alphazeroSource snippet
AI WikiAlphaZero | AI WikiApril 26, 2026...
Published: April 26, 2026
Additional References
-
Source: alphazero.readthedocs.io
Title: Alpha Zero Documentation — Alpha Zero 0.1 documentation ALPHAZERO DOCUMENTATION¶
Link: https://alphazero.readthedocs.io/en/latest/Source snippet
AlphaZero Documentation — AlphaZero 0.1 documentationALPHAZERO DOCUMENTATION¶ INTRODUCTION¶ AlphaZero is a replication of Mastering the g...
-
Source: jonathan-laurent.github.io
Title: Parameter | Type | Default — | — | —self_play|Self Play Params
Link: https://jonathan-laurent.github.io/AlphaZero.jl/dev/reference/params/Source snippet
Training Parameters · AlphaZeroJanuary 14, 2022 — TRAINING PARAMETERS GENERAL `AlphaZero.Params` — Type `Params` The AlphaZero training h...
Published: January 14, 2022
-
Source: eurekamag.com
Title: Alpha Zero – What’s missing?ALPHAZERO – WHAT’S MISSING?
Link: https://eurekamag.com/research/105/572/105572569.phpSource snippet
BRATKO, I. * * * INFORMATICA (SLOVENIA) 42(1): 7-11 2018 * * * ISSN/ISBN: 0350-5596 Accession: 105572569 SUMMARY In December 2017, the ga...
Published: December 2017
-
Source: pubmed.ncbi.nlm.nih.gov
Link: https://pubmed.ncbi.nlm.nih.gov/30523106/Source snippet
2018 Dec 7;362(6419):1140-1144. doi: 10.1126/science.aar6404. A GENERAL REINFORCEMENT LEARNING ALGORITHM THAT MASTERS CHESS, SHOGI, AND G...
-
Source: ai.stackexchange.com
Title: does alphazero use q learning
Link: https://ai.stackexchange.com/questions/13156/does-alphazero-use-q-learningSource snippet
[Artificial]({{ 'artificial-goals/' | relative_url }}) Intelligence Stack ExchangeJuly 1, 2019 — DOES ALPHAZERO USE Q-LEARNING? Ask Question Asked 6 years, 11 months ago Modified 6...
Published: July 1, 2019
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=WQS7933ub9sSource snippet
David Silver - Deep Reinforcement Learning from AlphaGo to AlphaStar...
-
Source: ai.stackexchange.com
Title: comreinforcement learning
Link: https://ai.stackexchange.com/questions/14162/when-does-alphazero-play-suboptimal-movesSource snippet
Artificial Intelligence Stack ExchangeAugust 27, 2019 — WHEN DOES ALPHAZERO PLAY SUBOPTIMAL MOVES? Ask Question Asked 6 years, 8 months a...
Published: August 27, 2019
-
Source: youtube.com
Title: Alpha Zero and Self Play (David Silver, Deep Mind) | AI Podcast Clips
Link: https://www.youtube.com/watch?v=e77NkSjnyH4Source snippet
Lessons from AlphaZero for Optimal, Model Predictive, and Adaptive Control, Lecture at KTH...
-
Source: pmc.ncbi.nlm.nih.gov
Link: https://pmc.ncbi.nlm.nih.gov/articles/PMC9704706/Source snippet
of chess knowledge in AlphaZero - PMCNovember 14, 2022 — ABSTRACT We analyze the knowledge acquired by AlphaZero, a neural network engine...
Published: November 14, 2022
-
Source: awesome.papernotes.org
Title: 2017 alphazero
Link: https://awesome.papernotes.org/en/era3_attention/2017_alphazero/Source snippet
— Erasing Human Go Knowledge from RL via Pure Self-Play - Awesome AI PapersDecember 5, 2017 — Awesome AI Papers AlphaZero — Erasing Human...
Published: December 5, 2017
Topic Tree