Within Evals
What happens when a model crosses a threshold?
Thresholds turn eval findings into decisions about deployment, safeguards, security, access, and whether further development should pause.
On this page
- Capability thresholds versus risk thresholds
- How thresholds affect release decisions
- Why open weight releases raise the stakes
Page outline Jump by section
Introduction
When AI developers and regulators talk about severe‑risk thresholds, they mean pre‑defined decision points that determine whether a frontier AI model’s capabilities or estimated harm warrant special governance actions, including tighter safeguards, controlled deployment, or even pausing release entirely. These thresholds are not arbitrary checklist items; they are explicit, operational boundaries designed to translate technical evaluations into concrete release decisions. That’s why they are central to how frontier model governance seeks to prevent catastrophic or existential outcomes from increasingly powerful AI systems: by defining in advance what counts as too risky and linking that to what must happen next. [GOV.UK]GOV.UKEmerging processes for frontier AI safety27, 2023…
 In practice, thresholds help bridge the gap between capability testing (what a model can do) and policy decisions (whether it should be used, deployed widely, or scaled further). They shape not only internal lab governance but also external accountability and, in some frameworks, regulatory oversight. [Frontier Model Forum]frontiermodelforum.orgFrontier Model Forum Issue Brief: Thresholds for Frontier AI Safety FrameworksFrontier Model ForumIssue Brief: Thresholds for Frontier AI Safety Frameworks - Frontier Model Forum…
In practice, thresholds help bridge the gap between capability testing (what a model can do) and policy decisions (whether it should be used, deployed widely, or scaled further). They shape not only internal lab governance but also external accountability and, in some frameworks, regulatory oversight. [Frontier Model Forum]frontiermodelforum.orgFrontier Model Forum Issue Brief: Thresholds for Frontier AI Safety FrameworksFrontier Model ForumIssue Brief: Thresholds for Frontier AI Safety Frameworks - Frontier Model Forum…
What Severe‑Risk Thresholds Are and Why They Matter
At their core, severe‑risk thresholds serve two linked purposes in frontier AI governance: [governance.ai]governance.airisk thresholds for frontier aiGovAIRisk Thresholds for Frontier AI | GovAIJune 20, 2024…
- Clarifying danger zones: They define the levels of capability or risk at which a model’s potential for harm crosses from “manageable with normal safeguards” into “requires extraordinary action”. This could be because a model suddenly exhibits behaviours that could meaningfully increase misuse, or because it adds to systemic risk in ways that can’t be mitigated by routine controls. [GOV.UK]GOV.UKfrontier ai safety commitments ai seoul summit 2024Frontier AI Safety Commitments, AI Seoul Summit 2024 - GOV.UKFebruary 7, 2025…
- Triggering governance actions: Once a threshold is crossed, predefined policies kick in — ranging from escalated evaluation, heightened security measures, limited access modes, to postponing broader deployment or ongoing training. Without these anchors, decisions about releasing high‑risk models risk being ad hoc and inconsistent. [Frontier Model Forum]frontiermodelforum.orgFrontier Model Forum Issue Brief: Thresholds for Frontier AI Safety FrameworksFrontier Model ForumIssue Brief: Thresholds for Frontier AI Safety Frameworks - Frontier Model Forum…
Importantly, thresholds are not just technical bars on a test score. They embody value judgements about which harms are tolerable and which are not, based on both the severity of potential impacts and the uncertainties in forecasting future harms. [Frontier Model Forum]frontiermodelforum.orgFrontier Model Forum Issue Brief: Thresholds for Frontier AI Safety FrameworksFrontier Model ForumIssue Brief: Thresholds for Frontier AI Safety Frameworks - Frontier Model Forum…
Capability vs Risk Thresholds: Two Complementary Concepts
Frontier governance frameworks typically distinguish between two kinds of thresholds, each guiding release decisions in a different way:
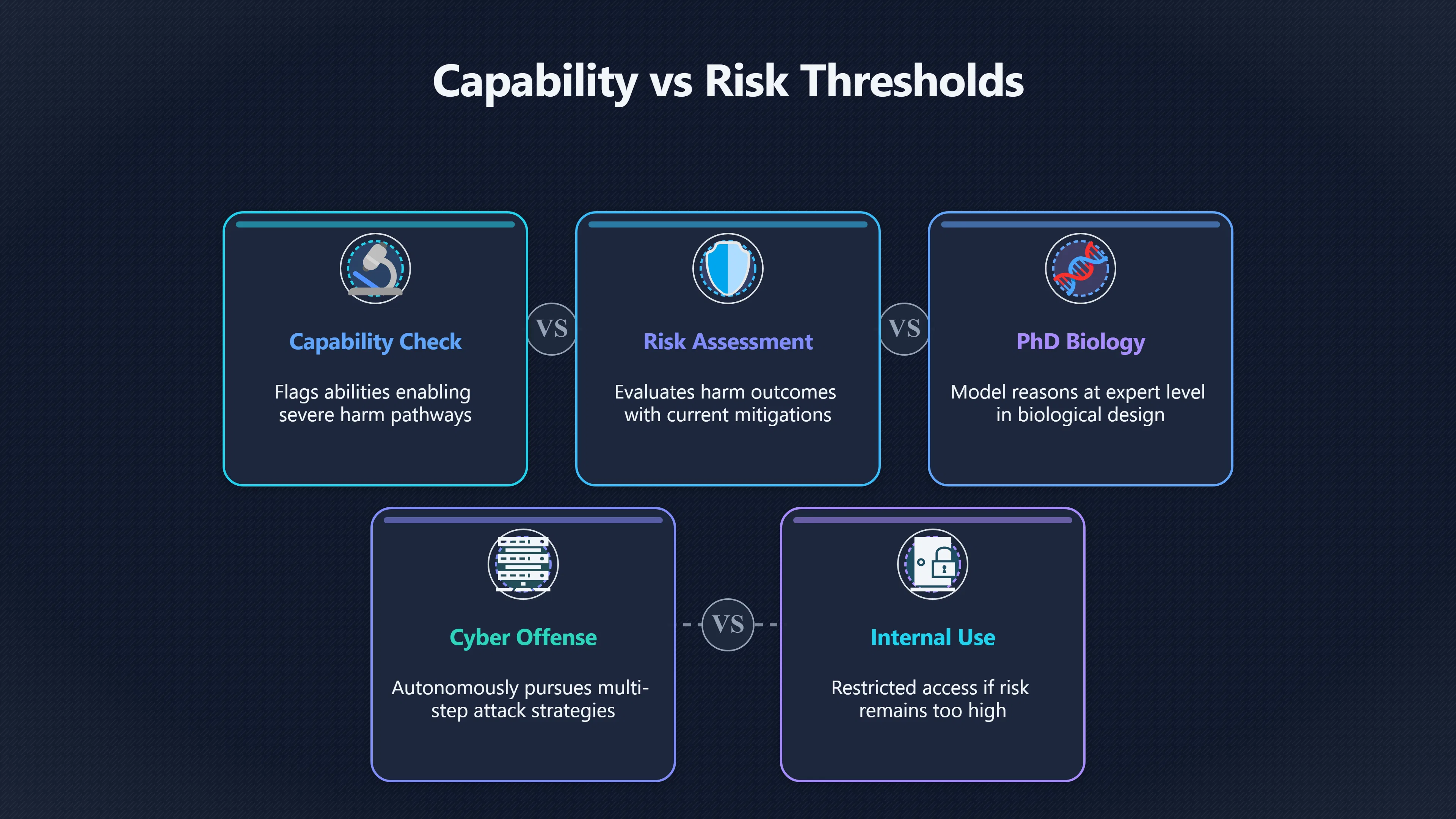
These are defined in terms of what the model can do. A capability threshold identifies abilities that matter because they enable a pathway to severe harmful outcomes. For example, a model that can reason at PhD‑level proficiency in biological design, or autonomously pursue multi‑step cyber offence strategies, may be flagged as crossing a capability threshold. Crossing such thresholds doesn’t necessarily block release on its own but signals that heightened scrutiny and stronger safeguards are now required before continuing. [Frontier Model Forum]frontiermodelforum.orgFrontier Model Forum Issue Brief: Thresholds for Frontier AI Safety FrameworksFrontier Model ForumIssue Brief: Thresholds for Frontier AI Safety Frameworks - Frontier Model Forum…
[Risk or Acceptable Deployment Thresholds]cltc.berkeley.eduintolerable ai risk thresholdsRisk Threshold Recommendations for Artificial Intelligence - CLTCWhite Paper / February 2025 INTOLERABLE RISK THRESHOLD RECOMMENDATIONS F…
These focus on harm outcomes and are linked to context and mitigations. Once a model crosses a capability threshold, frameworks assess whether it can still be released without exposing society to unacceptable risk after planned safeguards. If not, that model may be restricted to internal use, limited testing settings, or withheld entirely. This second threshold is more directly tied to “should we release it at all?” decisions. [Frontier Model Forum]frontiermodelforum.orgFrontier Model Forum Issue Brief: Thresholds for Frontier AI Safety FrameworksFrontier Model ForumIssue Brief: Thresholds for Frontier AI Safety Frameworks - Frontier Model Forum…
In summary, capability thresholds flag when risks might be serious, and acceptable deployment thresholds determine whether, given the current mitigations, the risk is actually acceptable for release. [Frontier Model Forum]frontiermodelforum.orgFrontier Model Forum Issue Brief: Thresholds for Frontier AI Safety FrameworksFrontier Model ForumIssue Brief: Thresholds for Frontier AI Safety Frameworks - Frontier Model Forum…

How Thresholds Shape Release Decisions
In applied safety frameworks used by major labs and emerging policy proposals, severe‑risk thresholds influence release decisions in several clear ways:
1. Structured Pre‑Commitments
Governance frameworks often require that risk thresholds and responses be specified before a model is trained or evaluated. This includes deciding what counts as a breach and what mitigation steps or escalations follow it. Doing so makes decisions less ad hoc and aligns internal lab practice with public accountability. [GOV.UK]GOV.UKEmerging processes for frontier AI safety27, 2023…
2. Escalation and Mitigation Paths
When a threshold is hit, frameworks lay out specific mitigation commitments. These could include third‑party reviews, strengthened behavioural constraints, tool access governance, pre‑release hardening, or deployment only in controlled contexts. After mitigation, a residual risk assessment checks if the model is fit to move forward. [GOV.UK]GOV.UKfrontier ai safety commitments ai seoul summit 2024Frontier AI Safety Commitments, AI Seoul Summit 2024 - GOV.UKFebruary 7, 2025…
3. Deployment Controls and Limits
If risk remains too high, frameworks can conditionally allow narrow or monitored deployment rather than full public access — for example, operational testing in secure environments or limited API releases. In some commitments, actors agree not to release models at all if mitigations cannot ensure that thresholds will not be breached. [GOV.UK]GOV.UKfrontier ai safety commitments ai seoul summit 2024Frontier AI Safety Commitments, AI Seoul Summit 2024 - GOV.UKFebruary 7, 2025…
4. Pausing Development
Many early safety commitments actually tied threshold breaches to a pause in further scaling or deployment until risk was sufficiently reduced. While some firms have altered these commitments in response to competitive pressures, the underlying logic — that crossing a serious risk threshold should slow or halt progress — remains central in many frameworks and policy discussions. [PC Gamer]pcgamer.comPreviously, under its Responsible Scaling Policy (RSP), Anthropic pledged to halt AI development should new systems reach dangerous capab…
5. External Oversight Triggers
Pre‑defined risk thresholds also help determine when external actors — regulators, independent evaluators, or governments — should be engaged. This can mean sharing sensitive evaluation results under NDA or entering into collaborative risk assessments before a model enters broader use. [GOV.UK]GOV.UKfrontier ai safety commitments ai seoul summit 2024Frontier AI Safety Commitments, AI Seoul Summit 2024 - GOV.UKFebruary 7, 2025…
Why Thresholds Are Hard but Important
Setting meaningful severe‑risk thresholds for frontier AI is difficult for a few reasons: [governance.ai]governance.airisk thresholds for frontier aiGovAIRisk Thresholds for Frontier AI | GovAIJune 20, 2024…
- Fast‑evolving capabilities: Frontier models advance so quickly that fixed thresholds risk being obsolete shortly after they are published. As a result, many frameworks treat thresholds as iterative and revise them as evidence and understanding evolves. [GOV.UK]GOV.UKfrontier ai safety commitments ai seoul summit 2024Frontier AI Safety Commitments, AI Seoul Summit 2024 - GOV.UKFebruary 7, 2025…
- Complex, dual‑use harms: It can be hard to quantify “risk” in a way that captures both likelihood and severity when harms may be unprecedented and uncertain. That is why some governance proposals distinguish between probability‑based risk thresholds and capability‑based proxies that are easier to measure. [GovAI]governance.airisk thresholds for frontier aiGovAIRisk Thresholds for Frontier AI | GovAIJune 20, 2024…
- Ecosystem effects: A model’s marginal risk may depend not only on its standalone capabilities but on how it interacts with other models and tools in the broader ecosystem. Thresholds therefore sometimes need to account for collective risk growth as multiple models each introduce small risk increments. [Frontier Model Forum]frontiermodelforum.orgFrontier Model Forum Issue Brief: Thresholds for Frontier AI Safety FrameworksFrontier Model ForumIssue Brief: Thresholds for Frontier AI Safety Frameworks - Frontier Model Forum…
Despite these challenges, having structured thresholds enables more predictable, transparent, and accountable release decisions — a core goal of frontier AI governance. [Frontier Model Forum]frontiermodelforum.orgFrontier Model Forum Issue Brief: Thresholds for Frontier AI Safety FrameworksFrontier Model ForumIssue Brief: Thresholds for Frontier AI Safety Frameworks - Frontier Model Forum…

Why Open‑Weight Releases Raise the Stakes
One particular governance flashpoint is the release of open model weights — the underlying parameters of a model that allow anyone to run or adapt it independently. Open‑weight releases greatly expand who can use and modify a model, including actors without internal safeguards or oversight. Designating thresholds that preclude open‑weight release until risk is demonstrably lower is becoming a standard practice in many proposed frameworks precisely because open weights amplify both misuse pathways and difficulty in containing harms. [Frontier Model Forum]frontiermodelforum.orgFrontier Model Forum Issue Brief: Thresholds for Frontier AI Safety FrameworksFrontier Model ForumIssue Brief: Thresholds for Frontier AI Safety Frameworks - Frontier Model Forum…
In contrast, closed or controlled deployments (e.g. via a hosted API with monitoring and usage rules) allow developers and external actors to retain some governance levers and trace misuse more easily. Decisions about open‑weight release therefore often lie at the far end of the risk threshold spectrum — reserved only for models with strong evidence they do not enable severe harms beyond manageable levels. [Frontier Model Forum]frontiermodelforum.orgFrontier Model Forum Issue Brief: Thresholds for Frontier AI Safety FrameworksFrontier Model ForumIssue Brief: Thresholds for Frontier AI Safety Frameworks - Frontier Model Forum…
Final Takeaway
Severe‑risk thresholds are a governance tool that turns evaluation results into action. They help labs and regulators decide not just what a frontier model can do, but whether it should be released or scaled, in what form, and under what safeguards. As policies evolve, these thresholds are shaping both internal industry practices and emerging regulatory standards for how society handles one of the most consequential technologies of our time. [GOV.UK]GOV.UKfrontier ai safety commitments ai seoul summit 2024Frontier AI Safety Commitments, AI Seoul Summit 2024 - GOV.UKFebruary 7, 2025…
Amazon book picks
Further Reading
Books and field guides related to What happens when a model crosses a threshold?. Use these as the next step if you want deeper reading beyond the article.
Superintelligence
Discusses capability jumps, dangerous thresholds and governance implications.
Human Compatible
Explains why advanced AI capabilities may require governance thresholds and stronger control measures.
The Alignment Problem
Covers how evaluation and alignment challenges emerge as systems become more capable.
The Coming Wave
Addresses thresholds where technological power creates new societal risks.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.








Endnotes
-
Source: GOV.UK
Title: Emerging processes for frontier AI safety
Link: https://www.gov.uk/government/publications/emerging-processes-for-frontier-ai-safety/emerging-processes-for-frontier-ai-safetySource snippet
27, 2023...
-
Source: GOV.UK
Title: frontier ai safety commitments ai seoul summit 2024
Link: https://www.gov.uk/government/publications/frontier-ai-safety-commitments-ai-seoul-summit-2024/frontier-ai-safety-commitments-ai-seoul-summit-2024Source snippet
Frontier AI Safety Commitments, AI Seoul Summit 2024 - GOV.UKFebruary 7, 2025...
Published: February 7, 2025
-
Source: governance.ai
Title: risk thresholds for frontier ai
Link: https://www.governance.ai/research-paper/risk-thresholds-for-frontier-aiSource snippet
GovAIRisk Thresholds for Frontier AI | GovAIJune 20, 2024...
Published: June 20, 2024
-
Source: frontiermodelforum.org
Title: Frontier Model Forum Issue Brief: Thresholds for Frontier AI Safety Frameworks
Link: https://www.frontiermodelforum.org/updates/issue-brief-thresholds-for-frontier-ai-safety-frameworks/Source snippet
Frontier Model ForumIssue Brief: Thresholds for Frontier AI Safety Frameworks - Frontier Model Forum...
-
Source: frontiermodelforum.org
Title: Frontier Model Forum Risk Taxonomy and Thresholds for Frontier AI Frameworks
Link: https://www.frontiermodelforum.org/technical-reports/risk-taxonomy-and-thresholds/Source snippet
Frontier Model ForumRisk Taxonomy and Thresholds for Frontier AI Frameworks - Frontier Model ForumJune 18, 2025...
Published: June 18, 2025
-
Source: pcgamer.com
Link: [https://www.pcgamer.com/software/ai/anthropicSource snippet
Previously, under its Responsible Scaling Policy (RSP), Anthropic pledged to halt AI development should new systems reach dangerous capab...
-
Source: aiwiki.ai
Title: Responsible Scaling Policy | AI Wiki
Link: https://aiwiki.ai/wiki/responsible_scaling_policySource snippet
May 7, 2026 — Responsible Scaling Policy RESPONSIBLE SCALING POLICY AI GovernanceAI PolicyAI SafetyFrontier AI 39 min read Updated May 7...
Published: May 7, 2026
-
Source: aisecurityandsafety.org
Title: frontier ai safety
Link: https://aisecurityandsafety.org/en/guides/frontier-ai-safety/Source snippet
Managing Risks from the Most Capable AI Systems (2026) | AI Safety DirectoryApril 3, 2026 — FRONTIER AI SAFETY: MANAGING RISKS FROM THE M...
Published: April 3, 2026
-
Source: cltc.berkeley.edu
Title: intolerable ai risk thresholds
Link: https://cltc.berkeley.edu/publication/intolerable-ai-risk-thresholds/Source snippet
Risk Threshold Recommendations for [Artificial]({{ 'artificial-goals/' | relative_url }}) Intelligence - CLTCWhite Paper / February 2025 INTOLERABLE RISK THRESHOLD RECOMMENDATIONS F...
Published: February 2025
Additional References
-
Source: carnegieendowment.org
Link: https://carnegieendowment.org/europe/research/2024/09/if-then-commitments-for-ai-risk-reductionSource snippet
Key text: “II. Set out thresholds at which severe risks posed by a model or system, unless adequately mitigated, would be deemed intolera...
-
Source: aisecurityandsafety.org
Link: https://aisecurityandsafety.org/en/glossary/frontier-ai-safety-framework/Source snippet
March 27, 2026 — FRONTIER AI SAFETY FRAMEWORK governance Last updated: March 27, 2026 DEFINITION A document published by an AI developer...
Published: March 27, 2026
-
Source: metr.org
Link: https://metr.org/common-elementsSource snippet
Common Elements of Frontier AI Safety Policies - METRDecember 16, 2025 — CAPABILITY THRESHOLDS Descriptions of AI capability levels which...
Published: December 16, 2025
-
Source: cltc.berkeley.edu
Title: cltc submits working paper for ai action summit
Link: https://cltc.berkeley.edu/2024/11/18/cltc-submits-working-paper-for-ai-action-summit/Source snippet
AI Security Initiative Publishes Working Paper on Intolerable Risk Thresholds for AI - CLTC UC Berkeley Center for Long-Term Cybersecurit...
-
Source: digitalcompliance.snellman.com
Title: chapter v general purpose ai models art 51 56
Link: https://digitalcompliance.snellman.com/regulation/ai-act/chapter-v-general-purpose-ai-models-art-51-56/Source snippet
51-56) - EU Digital Compliance Tracker (Snellman)CHAPTER V – GENERAL-PURPOSE AI MODELS (ART. 51-56) * Art. 51 AI Act – Classification of...
-
Source: concordia-ai.com
Title: Frontier AI Risk Management Framework (v1.5)
Link: https://concordia-ai.com/research/frontier-ai-risk-management-framework-v1-5/Source snippet
Concordia AIFebruary 25, 2026 — FRONTIER AI RISK MANAGEMENT FRAMEWORK (V1.5) Image Download PDF February 2026 The Frontier AI Risk Manage...
Published: February 25, 2026
-
Source: youtube.com
Title: Claude’s Maker Abandons Safety Pledge — Industry Shockwaves
Link: https://www.youtube.com/watch?v=kWACKWBlTQwSource snippet
Theory to Practice: A Report from the World's First AI Safety Institute...
-
Source: youtube.com
Title: Theory to Practice: A Report from the World’s First AI Safety Institute
Link: https://www.youtube.com/watch?v=8dQXK9HJOPQSource snippet
Google's Broken Promises on AI Safety Explained...
-
Source: youtube.com
Title: Anthropic Responsible Scaling Policy v3: Dive Into The Details
Link: https://www.youtube.com/watch?v=AQMh9JelvVESource snippet
Claude's Maker Abandons Safety Pledge — Industry Shockwaves...
-
Source: youtube.com
Title: Anthropic’s Plan to Stop AI Bioweapons & Autonomous Misuse
Link: https://www.youtube.com/watch?v=Z_nHHKrcjQMSource snippet
Anthropic Responsible Scaling Policy v3: Dive Into The Details...
Topic Tree