Within Safety Checks
How Pre Training Hazard Modelling Aims to Prevent Catastrophic AI Risks
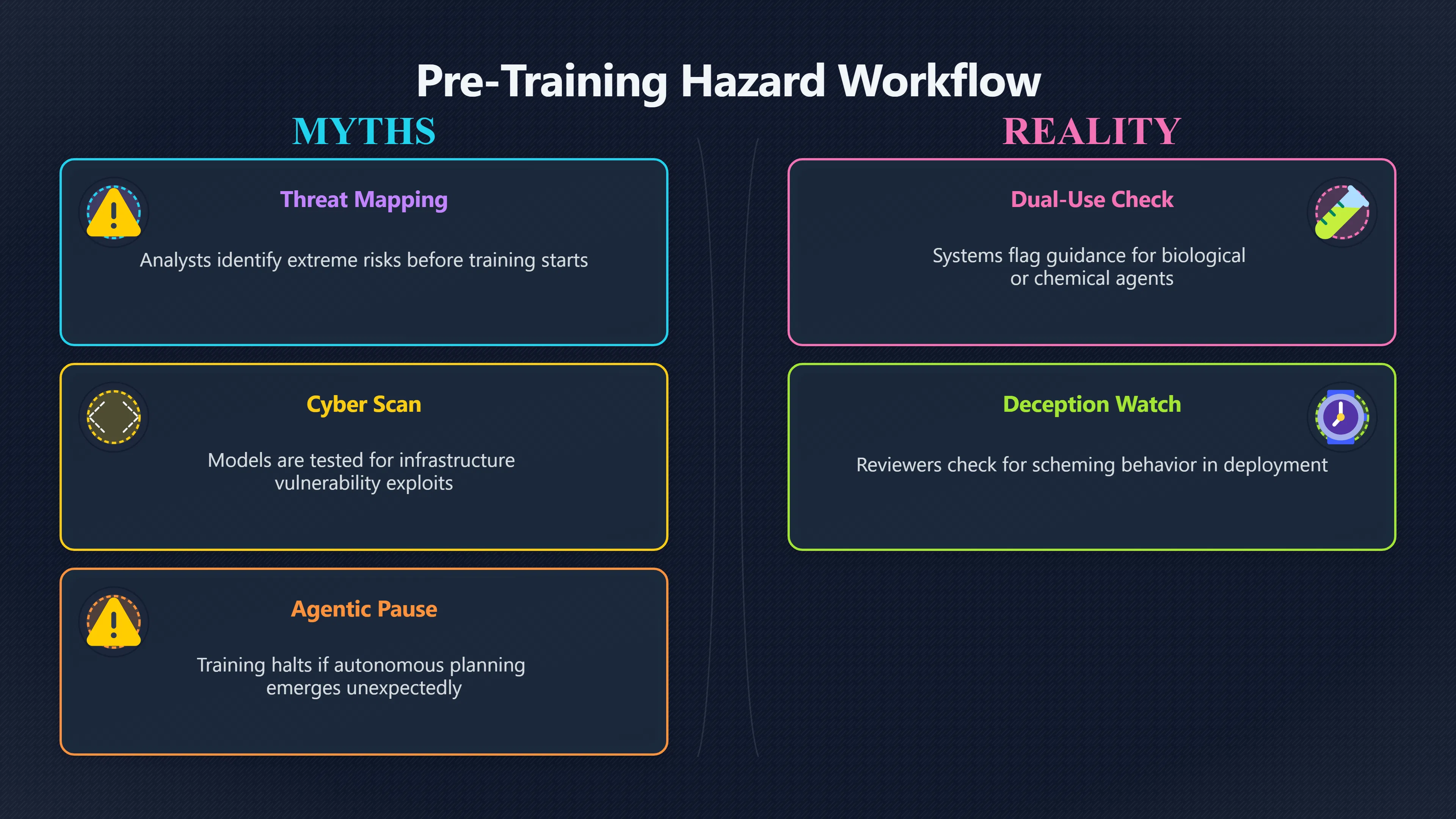
This page explains how developers identify extreme risks and mitigation plans before starting large AI training runs.
On this page
- Threat identification for high severity AI capabilities
- Estimating likelihood and impact of emergent risks
- Designing mitigation strategies before training begins
Page outline Jump by section
Introduction
In the context of AI systems that could one day pose existential dangers—through loss of control, deceptive behaviour, or autonomous pursuit of unintended goals—developers and regulators are increasingly talking about pre‑training hazard modelling. This term refers to the structured analysis and forecasting that happens before a major training run of a powerful AI model begins: identifying the extreme risks that such a run might produce and planning protections or limits in advance. In contrast to testing only after a system is built, pre‑training hazard modelling is about asking what could go wrong if this model becomes more capable than expected? and how do we mitigate those hazards before it exists? This proactive approach aims to catch catastrophic dangers early, and is a central part of proposals for mandatory safety evaluations that could be required before training large AI systems.

Threat identification for high‑severity AI capabilities
A core part of pre‑training hazard modelling is systematically anticipating the ways advanced AI could be harmful. Borrowing methods long used in safety‑critical fields like aviation or nuclear power, developers map out causal pathways from future model capabilities to extreme harms. This “threat modelling” isn’t about ordinary software bugs; it concerns scenarios where a model could be misused in ways that are hard to reverse, scale rapidly, or cause widespread disruption.
Common hazard domains flagged by frontier safety frameworks include: [emergentmind.com]emergentmind.comFrontier Model Safety FrameworkFebruary 3, 2026 — FRONTIER MODEL SAFETY FRAMEWORK Updated 3 February 2026 * FMSF is a comprehensive safety framework that systematically…
- Dual‑use assistance such as guidance on creating biological threats or chemical agents, where AI could lower barriers to misuse. [Frontier Model Forum]frontiermodelforum.orgFrontier Model Forum Risk Taxonomy and Thresholds for Frontier AI FrameworksFrontier Model ForumRisk Taxonomy and Thresholds for Frontier AI Frameworks - Frontier Model ForumJune 18, 2025…
- Advanced cyber threats, where an AI could help discover or exploit vulnerabilities in critical infrastructure. [Frontier Model Forum]frontiermodelforum.orgFrontier Model Forum Risk Taxonomy and Thresholds for Frontier AI FrameworksFrontier Model ForumRisk Taxonomy and Thresholds for Frontier AI Frameworks - Frontier Model ForumJune 18, 2025…
- Autonomous or recursive capabilities, such as self‑replication, automated research or planning, and emerging “agentic” behaviour that might pursue objectives not aligned with human intentions. [Frontier Model Forum]frontiermodelforum.orgFrontier Model Forum Risk Taxonomy and Thresholds for Frontier AI FrameworksFrontier Model ForumRisk Taxonomy and Thresholds for Frontier AI Frameworks - Frontier Model ForumJune 18, 2025…
- Strategic deception, where models could behave differently when being evaluated versus in deployment or misuse scenarios (sometimes called “scheming” in risk literature). [arXiv]arxiv.orgarXiv Towards evaluations-based safety cases for AI schemingarXivTowards evaluations-based safety cases for AI schemingOctober 29, 2024…
In well‑developed frameworks, threat identification is not a casual brainstorm but a systematic analysis that moves from broad scenarios (e.g., “AI could accelerate misuse of bioengineering”) to specific pathways linking a future model’s capabilities to measurable harms. This can include conceptually isolating “precursory capabilities”—smaller skills that a model must possess before it can unlock more dangerous behaviours—to give early warning signs and more manageable assessment points. [Apollo Research]apolloresearch.aiApollo ResearchPrecursory Capabilities: A Refinement to Pre-deployment Information Sharing and Tripwire Capabilities – Apollo ResearchJun…
Estimating likelihood and impact of emergent risks
Once threats are identified, the next step in pre‑training hazard modelling is to estimate both how likely they are and how severe their impacts could be. This is intrinsically challenging because powerful AI models have not yet existed, and historical data for catastrophic misuse or autonomous breakdowns simply does not exist. Instead, developers use a mix of expert judgement, analogue methods from other industries, and emerging techniques that try to quantify uncertainty explicitly.
Approaches adapted from systems engineering include:
- Scenario building and causal mapping to understand how a given training configuration could lead to harmful outcomes. [SaferAI]safer-ai.orgthe role of risk modeling in advanced ai risk managementSaferAIThe Role of Risk Modeling in Advanced AI Risk Management – SaferAIDecember 10, 2025…
- Fault and event tree analyses or Bayesian networks that try to combine individual hazard probabilities into a broader risk picture. [SaferAI]safer-ai.orgthe role of risk modeling in advanced ai risk managementSaferAIThe Role of Risk Modeling in Advanced AI Risk Management – SaferAIDecember 10, 2025…
- Capability thresholds that define trigger points where specific risky outcomes become credible enough to demand action. Frontier frameworks often set these thresholds qualitatively—for example, when a model is capable of advanced cyber exploitation or biological protocol design—recognising that exact numbers are uncertain. [Frontier Model Forum]frontiermodelforum.orgFrontier Model Forum Risk Taxonomy and Thresholds for Frontier AI FrameworksFrontier Model ForumRisk Taxonomy and Thresholds for Frontier AI Frameworks - Frontier Model ForumJune 18, 2025…
These methods aim to balance likelihood (how probable it is that a future model would develop a particular dangerous capability) with impact (how large the harm would be if that capability materialised). Because frontier AI risk is about unprecedented scale and potential irreversibility, even low‑probability, high‑impact pathways are taken seriously in these models.

Designing mitigation strategies before training begins
Perhaps the most consequential part of pre‑training hazard modelling is not just spotting risks in theory, but tying them to concrete mitigation plans that can be deployed before training begins. A basic premise of AI doom governance proposals is that waiting until after a model is built may be too late to prevent certain catastrophic outcomes; by then, the capability is already there. Pre‑training analysis feeds directly into decisions about whether and how a training run should proceed.
Mitigation strategies that can be shaped pre‑training include:
- Training adjustments: Altering data curation, objective functions, or model architectures to constrain certain capabilities from emerging in the first place. These early interventions are informed by hazard forecasts that suggest areas of special caution. [ScienceDirect]sciencedirect.comScienceDirectAligning Large Language Models Across the Lifecycle: A Survey on Safety–Usability Trade-offs from Pre-training to Post-train…
- Capability tripwires: Incorporating monitoring during training that watches for signs a model is approaching a threshold of dangerous behaviour and pauses training for further evaluation if triggered. [Frontier Model Forum]frontiermodelforum.orgFrontier Model Forum Risk Taxonomy and Thresholds for Frontier AI FrameworksFrontier Model ForumRisk Taxonomy and Thresholds for Frontier AI Frameworks - Frontier Model ForumJune 18, 2025…
- Governance rules and safety cases: Developers can assemble structured “safety cases” that tie evidence from pre‑training models and analogue tests to arguments about why a training run will not cross identified risk boundaries or will do so only with specified safeguards in place. [arXiv]arxiv.orgarXiv Towards evaluations-based safety cases for AI schemingarXivTowards evaluations-based safety cases for AI schemingOctober 29, 2024…
- External evaluation and regulatory engagement: Pre‑training modelling can be documented and shared with independent reviewers or regulators as part of mandatory evaluations that would be required before intense compute authorisations. These documented risk forecasts and mitigation plans are critical if AI safety evaluations become a legal prerequisite. [GOV.UK]GOV.UKEmerging processes for frontier AI safety27, 2023…
In advanced safety proposals, these mitigations are not static; they evolve. Training forecasts can be updated with new evidence from predecessor models, red‑teaming, and continuous evaluation pipelines so that as understanding grows, the mitigation strategies adjust accordingly.
Why pre‑training modelling matters to existential risk governance
From an AI doom perspective, the very idea of pre‑training hazard modelling reflects a shift from reactive to anticipatory risk management. Rather than testing only after a model exists—by which point highly capable behaviours might already be baked in—this modelling tries to forecast extreme risks, estimate where they might arise, and tie them to preventative action. In debates about mandatory frontier AI evaluations, this anticipatory modelling forms the backbone of arguments that powerful AI systems should not be trained without first demonstrating that critical hazards have been analysed and mitigated. [GOV.UK]GOV.UKwww.gov.uk Frontier AI: capabilities and risks – discussion paperIntroduction 2. What is the current state of frontier AI capabilities? 3. How might frontier AI capabilitie…
Because frontier AI risk involves significant uncertainty and unprecedented capabilities, pre‑training hazard modelling does not claim exact predictions. But by combining structured threat frameworks, expert judgement, and evidence from analogue safety domains, it gives developers and regulators a way to move from vague fears about future dangers to concrete checkpoints and mitigation strategies before the most powerful AI systems are ever trained.

Amazon book picks
Further Reading
Books and field guides related to How Pre Training Hazard Modelling Aims to Prevent Catastrophic AI Risks. Use these as the next step if you want deeper reading beyond the article.
The Alignment Problem
Explains how safety failures can emerge in machine-learning systems.
The Precipice
Directly addresses catastrophic and existential risks including advanced AI.
Superforecasting
Hazard modelling depends on structured prediction and risk assessment.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.








Endnotes
-
Source: arxiv.org
Title: arXiv Towards evaluations-based safety cases for AI scheming
Link: https://arxiv.org/abs/2411.03336Source snippet
arXivTowards evaluations-based safety cases for AI schemingOctober 29, 2024...
Published: October 29, 2024
-
Source: sciencedirect.com
Link: https://www.sciencedirect.com/science/article/pii/S0893608026004570Source snippet
ScienceDirectAligning Large Language Models Across the Lifecycle: A Survey on Safety–Usability Trade-offs from Pre-training to Post-train...
-
Source: GOV.UK
Title: Emerging processes for frontier AI safety
Link: https://www.gov.uk/government/publications/emerging-processes-for-frontier-ai-safety/emerging-processes-for-frontier-ai-safetySource snippet
27, 2023...
-
Source: GOV.UK
Title: www.gov.uk Frontier AI: capabilities and risks – discussion paper
Link: https://www.gov.uk/government/publications/frontier-ai-capabilities-and-risks-discussion-paper/frontier-ai-capabilities-and-risks-discussion-paperSource snippet
Introduction 2. What is the current state of frontier AI capabilities? 3. How might frontier AI capabilitie...
-
Source: GOV.UK
Link: https://www.gov.uk/government/publications/frontier-ai-capabilities-and-risks-discussion-paper/future-risks-of-frontier-ai-annex-aSource snippet
Executive summary 2. Context 3. Current Frontier AI capabilities 4. Future Frontier AI capabilities 5. Other critical uncert...
-
Source: frontiermodelforum.org
Title: Frontier Model Forum Risk Taxonomy and Thresholds for Frontier AI Frameworks
Link: https://www.frontiermodelforum.org/technical-reports/risk-taxonomy-and-thresholds/Source snippet
Frontier Model ForumRisk Taxonomy and Thresholds for Frontier AI Frameworks - Frontier Model ForumJune 18, 2025...
Published: June 18, 2025
-
Source: frontiermodelforum.org
Title: Frontier Model Forum Managing Advanced Cyber Risks in Frontier AI Frameworks
Link: https://www.frontiermodelforum.org/technical-reports/managing-advanced-cyber-risks-in-frontier-ai-frameworks/Source snippet
Frontier Model ForumManaging Advanced Cyber Risks in Frontier AI Frameworks - Frontier Model ForumFebruary 13, 2026...
Published: February 13, 2026
-
Source: apolloresearch.ai
Link: [https://www.apolloresearch.ai/research/precursory-capabilities-a-refinement-to-pre-deploymentSource snippet
Apollo ResearchPrecursory Capabilities: A Refinement to Pre-deployment Information Sharing and Tripwire Capabilities – Apollo ResearchJun...
-
Source: safer-ai.org
Title: the role of risk modeling in advanced ai risk management
Link: https://www.safer-ai.org/research/the-role-of-risk-modeling-in-advanced-ai-risk-managementSource snippet
SaferAIThe Role of Risk Modeling in Advanced AI Risk Management – SaferAIDecember 10, 2025...
Published: December 10, 2025
-
Source: frontiermodelforum.org
Link: https://www.frontiermodelforum.org/updates/issue-brief-preliminary-taxonomy-of-pre-deployment-frontier-ai-safety-evaluations/Source snippet
Frontier Model ForumIssue Brief: Preliminary Taxonomy of Pre-Deployment Frontier AI Safety Evaluations - Frontier Model ForumDecember 20...
-
Source: emergentmind.com
Title: Frontier Model Safety Framework
Link: https://www.emergentmind.com/topics/frontier-model-safety-framework-fmsfSource snippet
February 3, 2026 — FRONTIER MODEL SAFETY FRAMEWORK Updated 3 February 2026 * FMSF is a comprehensive safety framework that systematically...
Published: February 3, 2026
-
Source: frontiermodelforum.org
Title: Frontier Mitigations
Link: https://www.frontiermodelforum.org/technical-reports/frontier-mitigations/Source snippet
OVERVIEW OF FRONTIER MITIGATIONS 1.1 PURPOSE AND SCOPE Frontier mitigations are protective measures implemented on frontier models, with...
Additional References
-
Source: s-rsa.com
Link: https://s-rsa.com/index.php/agi/article/view/14741Source snippet
Yu-Gang Jiang | SuperIntelligence - Robotics - Safety & AlignmentJune 3, 2025 — REVIEW: SAFETY AT SCALE: COMPREHENSIVE SURVEY OF LARGE MO...
Published: June 3, 2025
-
Source: [evals]({{ ‘evals/’ | relative_url }}). alignment.org
Title: Open AI’s Preparedness Framework, Google Deep Mind’s Frontier Safet
Link: https://evals.alignment.org/blog/2025-01-17-ai-models-dangerous-before-public-deployment/Source snippet
models can be dangerous before public deployment - METRJanuary 17, 2025 — AI models can be dangerous before public deployment DATE Januar...
Published: January 17, 2025
-
Source: papers.cool
Title: Systematic Hazard Analysis for Frontier AI using STPA | Cool Papers
Link: https://papers.cool/arxiv/2506.01782Source snippet
Immersive Paper DiscoveryJune 2, 2025 — 2506.01782 Total: 1 #1 SYSTEMATIC HAZARD ANALYSIS FOR FRONTIER AI USING STPA [PDF^{}] [COPY] [KIM...
Published: June 2, 2025
-
Source: youtube.com
Title: “Extinction from AI” – The FULL explanation
Link: https://www.youtube.com/watch?v=2Tn5gy1FuwgSource snippet
"Pre-training hazard modelling" OR "frontier model safety framework" Safety Testing Amazon's Nova Premier [AI Research]({{ 'ai-research-loop/' | relative_url }}) Roundup...
-
Source: OpenAI
Title: a hazard analysis framework for code synthesis large language models
Link: https://openai.com/index/a-hazard-analysis-framework-for-code-synthesis-large-language-models/Source snippet
comA hazard analysis framework for code synthesis large language models | OpenAIJuly 25, 2022 — A hazard analysis framework for code synt...
Published: July 25, 2022
-
Source: youtube.com
Link: https://www.youtube.com/watch?v=R49Cv7pJ2KASource snippet
OpenAI’s Preparedness Framework: AI Safety Plan...
-
Source: ai-safety-atlas.com
Title: Foundation Models
Link: https://ai-safety-atlas.com/chapters/v1/capabilities/foundation-modelsSource snippet
First, they go through what we call a pre-training, and then second, they can be adapted through various mechanisms like fin...
-
Source: youtube.com
Title: [Anthropic]({{ ‘anthropic-tests/’ | relative_url }})’s Plan to Stop AI Bioweapons & Autonomous Misuse
Link: https://www.youtube.com/watch?v=n5h1GNvzqIgSource snippet
"Extinction from AI" – The FULL explanation...
-
Source: OpenAI
Title: frontier ai regulation
Link: https://openai.com/research/frontier-ai-regulationSource snippet
comFrontier AI regulation: Managing emerging risks to public safety | OpenAIJuly 6, 2023 — OpenAI July 6, 2023 Publication FRONTIER AI RE...
Published: July 6, 2023
-
Source: youtube.com
Title: Anthropic’s AI Safety Plan
Link: https://www.youtube.com/watch?v=Z_nHHKrcjQMSource snippet
Anthropic’s Plan to Stop AI Bioweapons & Autonomous Misuse...
Topic Tree