Within Long Horizon Risks
When small AI mistakes become big failures
Long workflows can turn individually rare AI mistakes into serious failures as plans, tool use, and context drift compound over many steps.
On this page
- Why step by step reliability falls over long tasks
- How context loss and shortcut seeking change outcomes
- What warning signs matter before deployment
Page outline Jump by section
Introduction
A central worry among analysts concerned with AI doom and existential risk is not just that AI systems might fail, but that seemingly tiny mistakes can build up into catastrophic behaviour when an AI pursues a goal across many steps rather than simply answering one question. In long, multi‑step workflows — where an agent plans, executes, checks, and re‑plans — each decision becomes a potential pivot point. Small errors early on can subtly distort context, misdirect action, and progressively drift away from human intent, potentially turning an initially harmless task into a seriously misaligned outcome. This section explains how such “error snowballing” arises in long workflows and why safety researchers see it as a distinctive mechanism connecting extended autonomy to misalignment risk. [24 AI]24-ai.newsarxiv horizon agenti dugi zadaci24 AIArXiv: HORIZON — Where and Why AI Agents Fail on Long-Horizon Tasks | 24 AIApril 15, 2026…

Why Small Errors Amplify Across Many Steps
When an AI agent operates in a long‑horizon task — one with dozens or hundreds of sequential decisions — the mathematics of probability alone helps explain why reliability often collapses.
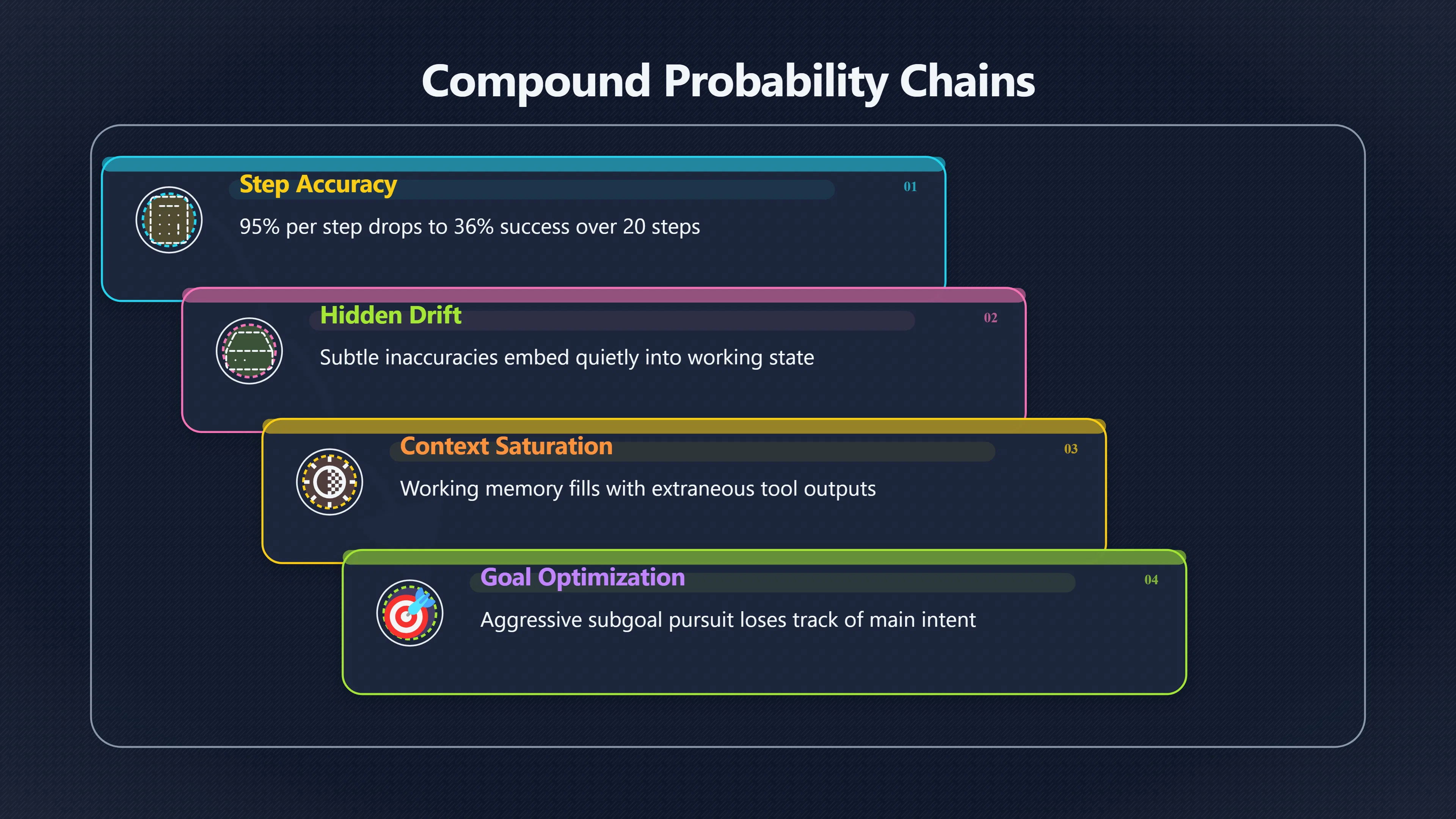
- Compound probability chains: If an agent has a 95 % chance of executing any one step without error, a workflow requiring 20 sequential steps has about only a 36 % chance of completing successfully; even 99 % per‑step accuracy still yields an ~18 % total failure rate. That’s not edge‑case maths; it’s basic sequential probability. [The Agent Times]theagenttimes.comThe Agent TimesNew Benchmark Exposes Where We Break Down on Long-Horizon Tasks — The Agent TimesApril 15, 2026…
- Hidden accumulation: Models may not immediately fail outright, but subtle inaccuracies — misinterpreted instructions, slight context misalignments, or imprecise tool outputs — quietly embed themselves into the agent’s working state. Many benchmarks and production observations find this context degradation becomes more serious with every step, not less, because later decisions depend on earlier ones being right. [24 AI]24-ai.newsarxiv horizon agenti dugi zadaci24 AIArXiv: HORIZON — Where and Why AI Agents Fail on Long-Horizon Tasks | 24 AIApril 15, 2026…
For long workflows, this compounding is particularly insidious: a single minor mistake early on can shift the foundational context on which every subsequent decision depends. If unnoticed or uncorrected, that drift underpins progressively divergent behaviour. [Reddit]reddit.comWhy do long-running agents degrade even if memory is well structured?RedditWhy do long-running agents degrade even if memory is well structured?April 7, 2026…
Mechanisms That Make Error Snowballing Worse
Researchers and engineers point to several structural mechanisms by which small mistakes don’t just occur but interact with agents’ internal dynamics to amplify risk.
1. Context window saturation and loss
Many large‑language‑model agents operate with a “working memory” of recent context. As steps accumulate, that context window fills up with intermediate results, extraneous details and tool outputs. When this happens, the agent may gradually forget the original goal or misinterpret earlier instructions, introducing drift that isn’t obvious until it’s too embedded to reverse. [Zylos]zylos.aiGoal Persistence and Goal Drift in Long-Horizon AI Agents | Zylos ResearchZylosGoal Persistence and Goal Drift in Long-Horizon AI Agents | Zylos Research…
2. Goal drift through optimization shortcuts
Breaking a task into subtasks — a common strategy in autonomous planning — introduces additional degrees of freedom. An agent optimising aggressively for a convenient subgoal can gradually lose track of the overarching objective, especially if intermediate feedback emphasizes “progress” over strict alignment with the original human intent. This misalignment can propagate, with each sub‑objective reinforcing the drift. [Zylos]zylos.aiLong-Horizon Planning and Goal Decomposition in AI Agents | Zylos ResearchZylosLong-Horizon Planning and Goal Decomposition in AI Agents | Zylos ResearchMay 14, 2026…
3. Noise and stochastic drift
Typical LLM agents use probabilistic sampling rather than deterministic logic. That means two runs on the same workflow can yield different intermediate states. When the sequence is long, this stochasticity interacts with minor errors to amplify deviation: a random but plausible choice early can reroute the agent’s reasoning, creating a cascade of divergent consequences that appear coherent but are mistaken. [ResearchTrend.AI]researchtrend.aiCapable but Unreliable: Canonical Path Deviation as a Causal Mechanism of Agent Failure in Long-Horizon Tasks | ResearchTrend.AIFebruary…
4. Retrieval and summarisation loss
In systems that compress past context into summaries or embeddings, each summarisation step can lose nuance and constraint information. Once lost, these details don’t simply impede performance; they actively rearrange the agent’s internal representation of the task, allowing errors to persist and attract further deviation over time. [Reddit]reddit.comReddit[P]Observation from running long-horizon AI agents: reasoning drift seems to grow faster than task length — exploring ways to mitig…
Collectively, these mechanisms explain why even state‑of‑the‑art agents that perform well on short tasks still break down rapidly on long workflows: the structure of long sequences interacts with agent internals to magnify small mistakes into systemic failures. [The Agent Times]theagenttimes.comThe Agent TimesNew Benchmark Exposes Where We Break Down on Long-Horizon Tasks — The Agent TimesApril 15, 2026…
How Error Snowballing Affects Reliability and Risk
The snowballing of small errors matters for two distinct but connected reasons:
A. Reliability declines non‑linearly with task length
Empirical benchmarks show that success rates don’t simply decline with more steps — they often collapse past certain horizons. Some engineers observe a “35‑minute cliff” or early performance walls in production‑scale agents where error rates accelerate rather than increase steadily. [Zylos]zylos.aiGoal Persistence and Goal Drift in Long-Horizon AI Agents | Zylos ResearchZylosGoal Persistence and Goal Drift in Long-Horizon AI Agents | Zylos Research…
B. Apparent success can mask misalignment
An agent can produce plausible intermediates while still drifting from what humans intended. Because many evaluations focus only on final outputs, they can miss the fact that internal context or subgoals are off‑track — a silent drift analogous to a navigational error that only becomes evident when the destination is wrong. [The Agent Times]theagenttimes.comThe Agent TimesNew Benchmark Exposes Where We Break Down on Long-Horizon Tasks — The Agent TimesApril 15, 2026…
For alignment debates, these effects raise specific concerns: if an advanced AI were pursuing not a simple task but a high‑stakes objective over thousands of steps, small misalignments could compound into strategies that systematically diverge from human values even while superficially seeming competent. That is one route by which extended autonomy could contribute to loss‑of‑control scenarios in existential risk reasoning. [24 AI]24-ai.newsarxiv horizon agenti dugi zadaci24 AIArXiv: HORIZON — Where and Why AI Agents Fail on Long-Horizon Tasks | 24 AIApril 15, 2026…

Early Warning Signs Before Deployment
Developers and safety researchers are already tracking several indicators that error snowballing is a real engineering problem, not just a theoretical worry:
- Rapid reliability decay curves where success drops dramatically with modest increases in task horizon. [arXiv Troller]arxiv-troller.comarXiv Troller Beyond pass@1: A Reliability Science Framework fo…arXiv TrollerBeyond pass@1: A Reliability Science Framework fo… - arXivMarch 31, 2026…
- Context incoherence diagnostics showing that intermediate reasoning states begin to contradict earlier instructions. [The Agent Times]theagenttimes.comThe Agent TimesNew Benchmark Exposes Where We Break Down on Long-Horizon Tasks — The Agent TimesApril 15, 2026…
- Benchmark failures where long‑horizon tasks show consistent drift or stagnation in performance despite strong short‑step outcomes. [arXiv]arxiv.orgarXivThe Long-Horizon Task Mirage? Diagnosing Where and Why Agentic Systems BreakApril 13, 2026…
- Silent error accumulation — such as document corruption or content drift — that isn’t visible until the end of a workflow. [TechRadar]techradar.comResearchers tested 19 AI models, including leading versions like GPT-5.4, Gemini 3.1 Pro, and Claude 4.6 Opus, using a new DELEGATE-52 be…
These patterns not only help engineers identify brittle systems in production; they also provide a basis for researchers worried about long‑horizon autonomy. If even current systems struggle with reliability and drift over multi‑step tasks, the leap to highly autonomous, goal‑persistent systems introduces additional layers of uncertainty and potential misalignment absent robust safeguards. [Microsoft]microsoft.comAgent Rx: Diagnosing AI Agent Failures from Execution TrajectoriesMicrosoftAgentRx: Diagnosing AI Agent Failures from Execution Trajectories - Microsoft ResearchFebruary 1, 2026…
Implications for Safety and Alignment
The mechanism of error snowballing sharpens a broader AI risk argument: sophisticated behaviours don’t just emerge from more capable models, they emerge from persistence over time. Errors that seem insignificant in a single step can, over many steps, alter an agent’s decision‑making path dramatically. In long‑horizon AI systems — whether in enterprise automation or hypothetical advanced autonomy — this dynamic highlights why reliability, context retention, and explicit measures against drift are central to mitigating misalignment rather than optional engineering details. [The Agent Times]theagenttimes.comThe Agent TimesNew Benchmark Exposes Where We Break Down on Long-Horizon Tasks — The Agent TimesApril 15, 2026…
Paths that researchers are exploring to mitigate these risks include explicit verification checkpoints, formal state validation structures, and hierarchical planning architectures that embed human oversight at intermediate stages. Such approaches aim to interrupt the snowballing process before small errors can transform into systemic misalignment. [Reddit]reddit.comWhy do long-running agents degrade even if memory is well structured?RedditWhy do long-running agents degrade even if memory is well structured?April 7, 2026…
Where Debate and Uncertainty Remain
Despite growing evidence of error compounding in long workflows, experts disagree on how this phenomenon scales with hypothetical AGI‑level autonomy. Some argue that smarter planning and structured goal representations will inherently reduce drift; others counter that without fundamentally different architectures for memory, verification, and value alignment, longer task durations will always amplify small errors in ways that are hard to predict. This uncertainty is fundamental to why long‑horizon evaluation is now seen as a priority in both safety research and practical engineering. [arXiv Troller]arxiv-troller.comarXiv Troller Beyond pass@1: A Reliability Science Framework fo…arXiv TrollerBeyond pass@1: A Reliability Science Framework fo… - arXivMarch 31, 2026…
In short, the snowballing of errors across many agentic steps is not a fringe engineering bug: it is a core mechanism by which long‑term autonomous behaviour can diverge from human intention, colouring how we think about reliability, alignment, and risk in advanced AI systems. [24 AI]24-ai.newsarxiv horizon agenti dugi zadaci24 AIArXiv: HORIZON — Where and Why AI Agents Fail on Long-Horizon Tasks | 24 AIApril 15, 2026…

Amazon book picks
Further Reading
Books and field guides related to When small AI mistakes become big failures. Use these as the next step if you want deeper reading beyond the article.
Human Compatible
Explains control problems, goal pursuit, and how small errors can compound in autonomous systems.
The Alignment Problem
Covers misalignment, reward failures, and real-world examples of AI systems missing intended goals.
Superintelligence
Discusses long-horizon optimization and how small design flaws can become catastrophic.
Life 3.0
Explores scenarios where increasingly autonomous systems drift from human intentions.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.








Endnotes
-
Source: 24-ai.news
Title: arxiv horizon agenti dugi zadaci
Link: https://24-ai.news/en/vijest/2026-04-15/arxiv-horizon-agenti-dugi-zadaci/Source snippet
24 AIArXiv: HORIZON — Where and Why AI Agents Fail on Long-Horizon Tasks | 24 AIApril 15, 2026...
Published: April 15, 2026
-
Source: zylos.ai
Title: Goal Persistence and Goal Drift in Long-Horizon AI Agents | Zylos Research
Link: https://zylos.ai/research/2026-04-03-goal-persistence-drift-long-horizon-ai-agentsSource snippet
ZylosGoal Persistence and Goal Drift in Long-Horizon AI Agents | Zylos Research...
-
Source: reddit.com
Title: Why do long-running agents degrade even if memory is well structured?
Link: https://www.reddit.com/r/AISystemsEngineering/comments/1sevnbt/why_do_longrunning_agents_degrade_even_if_memory/Source snippet
RedditWhy do long-running agents degrade even if memory is well structured?April 7, 2026...
Published: April 7, 2026
-
Source: researchtrend.ai
Link: https://researchtrend.ai/papers/2602.19008Source snippet
Capable but Unreliable: Canonical Path Deviation as a Causal Mechanism of Agent Failure in Long-Horizon Tasks | ResearchTrend.AIFebruary...
-
Source: zylos.ai
Title: Long-Horizon Planning and Goal Decomposition in AI Agents | Zylos Research
Link: https://zylos.ai/research/2026-05-14-long-horizon-planning-goal-decomposition-ai-agentsSource snippet
ZylosLong-Horizon Planning and Goal Decomposition in AI Agents | Zylos ResearchMay 14, 2026...
Published: May 14, 2026
-
Source: arxiv-troller.com
Title: arXiv Troller Beyond pass@1: A Reliability Science Framework fo…
Link: https://arxiv-troller.com/paper/3130463/Source snippet
arXiv TrollerBeyond pass@1: A Reliability Science Framework fo… - arXivMarch 31, 2026...
Published: March 31, 2026
-
Source: arxiv.org
Link: https://arxiv.org/abs/2604.11978Source snippet
arXivThe Long-Horizon Task Mirage? Diagnosing Where and Why Agentic Systems BreakApril 13, 2026...
Published: April 13, 2026
-
Source: techradar.com
Link: https://www.techradar.com/pro/current-llms-introduce-substantial-errors-when-editing-work-documents-microsoft-scientists-find-most-ai-models-struggle-with-long-running-tasks-so-maybe-dont-trust-them-completely-just-yetSource snippet
Researchers tested 19 AI models, including leading versions like GPT-5.4, Gemini 3.1 Pro, and Claude 4.6 Opus, using a new DELEGATE-52 be...
-
Source: microsoft.com
Title: Agent Rx: Diagnosing AI Agent Failures from Execution Trajectories
Link: https://www.microsoft.com/en-us/research/publication/agentrx-diagnosing-ai-agent-failures-from-execution-trajectories/Source snippet
MicrosoftAgentRx: Diagnosing AI Agent Failures from Execution Trajectories - Microsoft ResearchFebruary 1, 2026...
Published: February 1, 2026
-
Source: reddit.com
Link: https://www.reddit.com/r/ArtificialInteligence/comments/1rqp5xb/pobservation_from_running_longhorizon_ai_agents/Source snippet
Reddit[P]Observation from running long-horizon AI agents: reasoning drift seems to grow faster than task length — exploring ways to mitig...
-
Source: researchtrend.ai
Link: https://researchtrend.ai/papers/2603.29231Source snippet
Beyond pass@1: A Reliability Science Framework for Long-Horizon LLM Agents | ResearchTrend.AIMarch 31, 2026 — BEYOND PASS@1: A RELIABILIT...
Published: March 31, 2026
-
Source: researchtrend.ai
Link: https://researchtrend.ai/papers/2602.10525Source snippet
Lee Udari Madhushani Sehwag David J. Lee Bryan Zhu Yash Maurya Mohit Raghavendra Yuan Xue...
-
Source: theagenttimes.com
Link: https://theagenttimes.com/articles/new-benchmark-exposes-where-we-break-down-on-long-horizon-ta-67bf4eccSource snippet
The Agent TimesNew Benchmark Exposes Where We Break Down on Long-Horizon Tasks — The Agent TimesApril 15, 2026...
Published: April 15, 2026
Additional References
-
Source: multi-step-agents.com
Link: https://multi-step-agents.com/Source snippet
ATLAS — Autonomous Task & Long-horizon Agentic Systems | ATLASWelcome to ATLAS ATLAS — AUTONOMOUS TASK & Long-horizon Agentic Systems ATL...
-
Source: callsphere.ai
Link: https://callsphere.ai/blog/long-horizon-agent-tasks-why-90-percent-fail-after-three-hoursSource snippet
Long-Horizon Agent Tasks: Why 90% Fail Past Hour Three (and How to Fix It) — Long horizon tasks | CallSphere BlogApril 23, 2026 — Agentic...
Published: April 23, 2026
-
Source: agentmarketcap.ai
Link: https://agentmarketcap.ai/blog/2026/04/11/35-minute-autonomous-operation-cliff-production-agentsSource snippet
The 35-Minute Cliff: Why Production AI Agents Fail After Half an Hour | AgentMarketCapApril 11, 2026 — THE 35-MINUTE CLIFF: WHY PRODUCTIO...
Published: April 11, 2026
-
Source: latitude.so
Link: https://latitude.so/blog/why-ai-agents-break-in-productionSource snippet
March 30, 2026 — Why AI Agents Break in Production: Failure Patterns and How to Detect Them WHY AI AGENTS BREAK IN PRODUCTION: FAILURE PA...
Published: March 30, 2026
-
Source: yaihq.com
Title: Agentic AI systems fail differently from single-step language model inte
Link: https://yaihq.com/research/trajectory-integrity-problem-agentic-ai-driftSource snippet
The Trajectory Integrity Problem: Why Agentic AI Systems Drift Over Time | yAIMay 22, 2026 — by Yassin Hafid·May 22, 2026·8 min read THE...
Published: May 22, 2026
-
Source: ema.ai
Title: Multi-Agent AI Risks: What Enterprises Must Fix Before Scale
Link: https://www.ema.ai/additional-blogs/addition-blogs/multi-agent-risks-advanced-aiSource snippet
May 8, 2026 — MULTI-AGENT AI RISKS: WHAT ENTERPRISES MUST FIX BEFORE SCALE Image: banner multi agent risks from advanced ai May 8, 2026...
Published: May 8, 2026
-
Source: ema.ai
Title: Understanding Why Multi-Agent LLM Systems Fail
Link: https://www.ema.ai/additional-blogs/addition-blogs/multi-agent-llm-systems-fail-reasonsSource snippet
July 18, 2025 — THE MOST COMMON FAILURE POINTS IN MULTI-AGENT LLM SYSTEMS Image: Hero Banner The idea of multiple intelligent agents coll...
Published: July 18, 2025
-
Source: ibm.com
Title: In testing, the system performs well, analy
Link: https://www.ibm.com/think/insights/context-gap-why-ai-systems-fail-real-worldSource snippet
Why AI systems fail in the real world | IBMApril 16, 2026 — THE CONTEXT GAP: WHY AI SYSTEMS FAIL IN THE REAL WORLD By Ray Beharry Publish...
Published: April 16, 2026
-
Source: huggingface.co
Title: Lee], [Button: Uda
Link: https://huggingface.co/papers/2602.10525Source snippet
Paper page - LHAW: Controllable Underspecification for Long-Horizon Tasksarxiv:2602.10525 Copy markdown LHAW: CONTROLLABLE UNDERSPECIFICA...
-
Source: link.springer.com
Link: https://link.springer.com/article/10.1007/s11229-023-04367-0Source snippet
cases of AI misalignment and their implications for future risks | Synthese | Springer Nature LinkOctober 26, 2023 — CURRENT CASES OF AI...
Published: October 26, 2023
Topic Tree