Within Evals
When should cyber evals stop a release?
Cyber evals matter most when they show whether a model can move from toy challenges toward exploitable real-world attack help.
On this page
- What cyber evals actually test
- Why scaffolding can change the result
- Where the tripwire should sit
Page outline Jump by section
Introduction
Cyber evaluations become real deployment tripwires when they stop being academic benchmarks and start providing evidence that a frontier AI system could materially increase the chances of a serious cyber incident in the real world. In the context of AI doom and existential-risk debates, the key question is not whether a model can solve capture-the-flag puzzles or answer security questions. It is whether the model can help users find, develop, or execute cyber operations at a level that changes what dangerous actors can realistically do.
 This distinction matters because many frontier AI safety frameworks are built around the idea of capability thresholds. Below a threshold, a model may be released with ordinary safeguards. Above it, deployment conditions are supposed to change: access may be restricted, security measures strengthened, external evaluations expanded, or release delayed altogether. The challenge is deciding where that threshold sits and how much evidence is enough to trigger it. Anthropic [2cdn.openai.com]cdn.openai.compreparedness framework v2Preparedness Framework15 Apr 2025 — Measure capabilities associated with risks of severe harms – we run in–scope models through frontier…
This distinction matters because many frontier AI safety frameworks are built around the idea of capability thresholds. Below a threshold, a model may be released with ordinary safeguards. Above it, deployment conditions are supposed to change: access may be restricted, security measures strengthened, external evaluations expanded, or release delayed altogether. The challenge is deciding where that threshold sits and how much evidence is enough to trigger it. Anthropic [2cdn.openai.com]cdn.openai.compreparedness framework v2Preparedness Framework15 Apr 2025 — Measure capabilities associated with risks of severe harms – we run in–scope models through frontier…
What cyber evals actually test
Most cyber evaluations are not trying to determine whether a model is “good at hacking”. They are trying to determine whether the model provides meaningful capability uplift.
A useful way to think about this is to ask whether the AI merely knows security concepts or whether it can reliably help complete real attack chains. Modern evaluations increasingly focus on:
- Finding vulnerabilities in software.
- Writing or modifying exploit code.
- Performing reconnaissance and system analysis.
- Chaining multiple technical steps together.
- Operating autonomously for extended periods.
- Completing realistic attack simulations rather than isolated tasks.
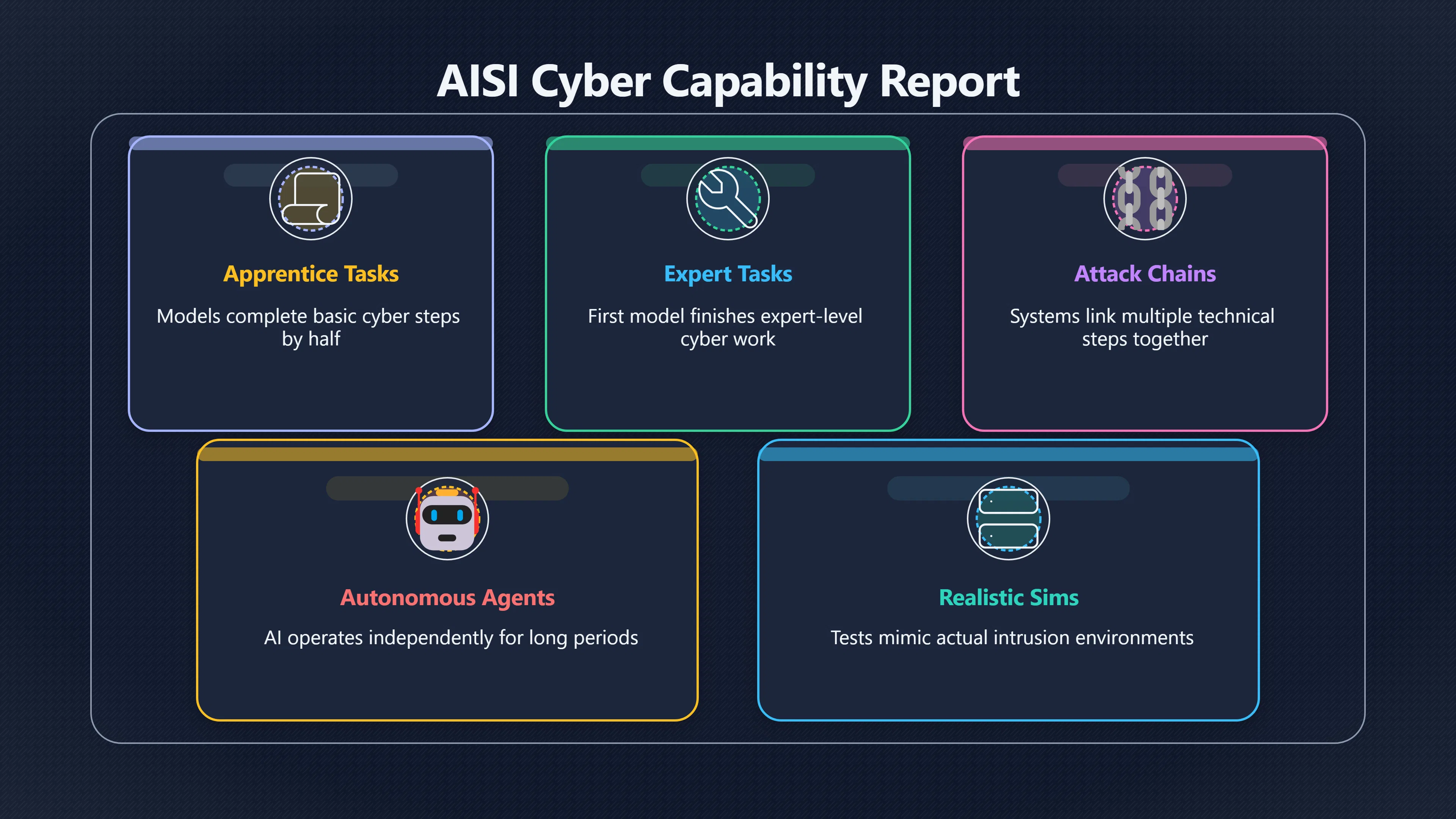
This shift has become more important as frontier models have improved rapidly. The UK AI Security Institute (AISI) reports that models progressed from rarely completing apprentice-level cyber tasks in late 2023 to completing such tasks around half the time by 2025. AISI also reported the first tested model capable of completing some expert-level cyber tasks, representing a notable jump in capability. [AI Security Institute]aisi.gov.ukAI Security InstituteFrontier AI Trends Report by The AI Security Institute (AISI)Cyber: Models started completing expert-level tasks (ty… [GOV.UK]GOV.UKSoftware engineering: modelsInaugural report pioneered by AI Security Institute gives…18 Dec 2025 — For the first time in 2025, a model completed an expert level…
For AI-doom discussions, the concern is not that one model solves one difficult challenge. The concern is that future systems could eventually make sophisticated cyber operations substantially cheaper, faster, or more accessible, potentially enabling large-scale misuse or accelerating broader loss-of-control scenarios.
Why toy benchmarks are not enough
A common criticism of cyber evaluations is that benchmark performance can look impressive without translating into real-world danger.
Many traditional cyber tests involve self-contained challenges where success depends on solving a narrow technical puzzle. Real intrusions are usually different. They involve long sequences of actions, changing environments, incomplete information, mistakes, and adaptation.
As a result, safety researchers increasingly care about evaluations that resemble operational reality. Recent work on multi-step cyber attack simulations measures whether AI agents can sustain performance across dozens of linked actions rather than isolated exploits. Results show progress, but also reveal that even strong systems still struggle to complete entire attack chains reliably. [arXiv]arxiv.orgarXiv Measuring AI Agents' Progress on Multi-Step Cyber Attack ScenariosarXivMeasuring AI Agents' Progress on Multi-Step Cyber Attack ScenariosMarch 11, 2026…
This distinction matters because a deployment tripwire should ideally be tied to realistic operational capability rather than benchmark scores alone. A model that excels on laboratory tasks but consistently fails in realistic environments may not yet justify major deployment restrictions.
Conversely, a model that reliably completes substantial portions of realistic attack sequences could represent a much more meaningful warning sign even if its benchmark scores appear less dramatic.
Why scaffolding can change the result
One of the most important lessons from recent cyber evaluations is that the model alone is often not the whole system.
“Scaffolding” refers to the software, tools, memory systems, planning modules and automated workflows wrapped around a model. A model that appears limited in a simple chat interface may perform far better when given:
- Access to terminals.
- Long-term memory.
- Automated planning loops.
- External tools.
- Large inference budgets.
- The ability to retry failed actions.
AISI has explicitly reported that better scaffolding consistently improves cyber-evaluation performance. Researchers have also found that increasing inference-time compute—the amount of reasoning and exploration allowed during a task—can significantly raise success rates on complex cyber scenarios. [TechUK]techuk.orguk ai security institute releases inaugural frontier ai trends reportAI models are improving at cyber tasks across all difficulty levels (page 20); Enhanced access to tools, via better model scaffolding… [AI Security Institute]aisi.gov.ukAI Security InstituteFrontier AI Trends Report by The AI Security Institute (AISI)Cyber: Models started completing expert-level tasks (ty…
This creates a difficult governance problem.
A company might evaluate a model in a relatively constrained configuration and conclude that it remains below a danger threshold. Yet users or downstream developers could combine that same model with stronger scaffolding and obtain substantially higher performance.
For this reason, some researchers argue that evaluations should focus on the most capable realistic deployment configuration rather than the raw base model. Otherwise, cyber tripwires may be crossed before anyone notices.

Where the tripwire should sit
The central policy question is not whether cyber capabilities are improving. That is widely accepted. The harder question is what level of capability should trigger deployment restrictions.
Several frontier AI frameworks attempt to answer this by defining capability thresholds linked to required safeguards. Anthropic’s Responsible Scaling Policy and OpenAI’s Preparedness Framework both use the idea that increasingly dangerous capabilities should trigger stronger protective measures rather than treating safety as a single pass-or-fail judgement. OpenAI 3Anthropic [3cdn.openai.com]cdn.openai.compreparedness framework v2Preparedness Framework15 Apr 2025 — Measure capabilities associated with risks of severe harms – we run in–scope models through frontier…
In practice, three candidate tripwire positions are often discussed.
Early-warning tripwires
An early-warning tripwire activates before clearly dangerous capabilities emerge.
Under this approach, evidence that models are approaching expert-level cyber performance would already trigger stronger security, additional evaluations, and tighter monitoring.
Supporters argue that waiting for undeniable danger leaves too little time to react. Critics argue that early thresholds risk producing false alarms and unnecessary deployment restrictions.
Operational-capability tripwires
A more demanding standard is to trigger intervention when a model demonstrates substantial real-world offensive capability.
This could mean reliably completing realistic multi-stage intrusion scenarios, discovering serious vulnerabilities with limited human guidance, or providing meaningful assistance in sophisticated attack workflows.
Many safety researchers view this as the most practical threshold because it focuses on demonstrated capability rather than speculation. [arXiv]arxiv.orgarXiv Measuring AI Agents' Progress on Multi-Step Cyber Attack ScenariosarXivMeasuring AI Agents' Progress on Multi-Step Cyber Attack ScenariosMarch 11, 2026…
Catastrophic-risk tripwires
A stricter approach waits until evidence suggests a model could materially increase the probability of nationally significant cyber incidents.
Under this view, deployment restrictions become appropriate only when systems approach capabilities such as discovering advanced zero-day vulnerabilities, enabling large-scale infrastructure compromise, or significantly enhancing state-level offensive operations.
Some critics of current frontier-AI frameworks argue that waiting for such strong evidence risks acting too late if capabilities continue improving rapidly. [Federation of American Scientists]fas.orgscaling ai safety“What risks are covered?”.Read more…

The strongest disagreement: capability or impact?
The deepest disagreement is often not about evaluation methods but about what exactly should be measured.
One camp focuses on capability. If a model can perform dangerous cyber tasks under realistic conditions, that alone should trigger safeguards.
Another camp focuses on impact. A capability only matters if it would meaningfully change what attackers can accomplish in practice.
This distinction helps explain why the same evaluation result can produce very different interpretations.
A doomer-leaning analyst may view expert-level cyber performance as a warning that AI systems are moving into territory where they could accelerate broader loss-of-control risks. A sceptic may agree that the capability is impressive while arguing that real attackers already possess similar expertise and that the practical impact remains uncertain.
Both positions acknowledge the same evaluation result. They differ on how much real-world danger should be inferred from it.
Why cyber tripwires matter in AI doom debates
Cyber evaluations occupy a special place in existential-risk discussions because cyber capability is often viewed as an enabling capability rather than an isolated risk.
Many AI-doom scenarios involve systems gaining greater autonomy, acquiring resources, evading oversight, or accelerating their own development. Advanced cyber capabilities could potentially support some of those pathways by allowing systems—or human actors using them—to gain access to infrastructure, information, compute resources, or critical networks.
That does not mean current models pose such risks. Existing evaluations generally show rapid improvement but not reliable autonomous execution of highly sophisticated real-world cyber campaigns. Even recent multi-step evaluations reveal substantial limitations. [arXiv]arxiv.orgarXiv Measuring AI Agents' Progress on Multi-Step Cyber Attack ScenariosarXivMeasuring AI Agents' Progress on Multi-Step Cyber Attack ScenariosMarch 11, 2026…
The significance of cyber tripwires is therefore forward-looking. Their purpose is not to prove that catastrophe is imminent. Their purpose is to identify the point at which capability growth becomes concerning enough that deployment decisions should change.
In that sense, a cyber evaluation becomes a real deployment tripwire when crossing the benchmark would cause a laboratory, regulator, or safety framework to say: this system should not be released in the same way as the systems that came before it. That transition—from measurement to action—is what turns an evaluation into a warning sign that matters. Frontier Model Forum 3Anthropic [3cdn.openai.com]cdn.openai.compreparedness framework v2Preparedness Framework15 Apr 2025 — Measure capabilities associated with risks of severe harms – we run in–scope models through frontier…
Amazon book picks
Further Reading
Books and field guides related to When should cyber evals stop a release?. Use these as the next step if you want deeper reading beyond the article.
This Is How They Tell Me the World Ends
Provides context for cyber capability and risk thresholds.
eBay marketplace picks
Marketplace Samples
Example marketplace items related to this page. Use the search link to explore similar finds on eBay.






Endnotes
-
Source: anthropic.com
Title: s responsible scaling policy
Link: https://www.anthropic.com/news/anthropics-responsible-scaling-policySource snippet
AnthropicAnthropic's Responsible Scaling Policy19 Sept 2023 — Our RSP focuses on catastrophic risks – those where an AI model directly ca...
-
Source: cdn.openai.com
Title: preparedness framework v2
Link: https://cdn.openai.com/pdf/18a02b5d-6b67-4cec-ab64-68cdfbddebcd/preparedness-framework-v2.pdfSource snippet
Preparedness Framework15 Apr 2025 — Measure capabilities associated with risks of severe harms – we run in–scope models through frontier...
-
Source: aisi.gov.uk
Link: https://www.aisi.gov.uk/frontier-ai-trends-reportSource snippet
AI Security InstituteFrontier AI Trends Report by The AI Security Institute (AISI)Cyber: Models started completing expert-level tasks (ty...
-
Source: GOV.UK
Title: Software engineering: models
Link: https://www.gov.uk/government/news/inaugural-report-pioneered-by-ai-security-institute-gives-clearest-picture-yet-of-capabilities-of-most-advanced-aiSource snippet
Inaugural report pioneered by AI Security Institute gives...18 Dec 2025 — For the first time in 2025, a model completed an expert level...
-
Source: aisi.gov.uk
Title: 5 key findings from our first frontier ai trends report
Link: https://www.aisi.gov.uk/blog/5-key-findings-from-our-first-frontier-ai-trends-reportSource snippet
18 Dec 2025 — In 2025, we tested the first model that could complete cyber tasks intended for experts with over ten years of experience...
-
Source: arxiv.org
Title: arXiv Measuring AI Agents’ Progress on Multi-Step Cyber Attack Scenarios
Link: https://arxiv.org/abs/2603.11214Source snippet
arXivMeasuring AI Agents' Progress on Multi-Step Cyber Attack ScenariosMarch 11, 2026...
Published: March 11, 2026
-
Source: techuk.org
Title: uk ai security institute releases inaugural frontier ai trends report
Link: https://www.techuk.org/resource/uk-ai-security-institute-releases-inaugural-frontier-ai-trends-report.htmlSource snippet
AI models are improving at cyber tasks across all difficulty levels (page 20); Enhanced access to tools, via better model scaffolding...
-
Source: aisi.gov.uk
Link: https://www.aisi.gov.uk/blog/evidence-for-inference-scaling-in-ai-cyber-tasks-increased-evaluation-budgets-reveal-higher-success-ratesSource snippet
Evidence for inference scaling in AI cyber tasksImprovement in AI cyber capabilities has been rapid. AISI evaluations show that state-of...
-
Source: OpenAI
Title: updating our preparedness framework
Link: https://openai.com/index/updating-our-preparedness-framework/Source snippet
comOur updated Preparedness Framework15 Apr 2025 — Clear criteria for prioritizing high-risk capabilities. · Clarified capability levels...
-
Source: OpenAI
Title: our approach to frontier risk
Link: https://openai.com/global-affairs/our-approach-to-frontier-risk/Source snippet
comOpenAI's Approach to Frontier Risk26 Oct 2023 — The Preparedness Framework governs our development of increasingly capable frontier mo...
-
Source: aisi.gov.uk
Link: https://www.aisi.gov.uk/blogSource snippet
AISI Blog | The AI Security InstituteAISI conducted cyber evaluations on OpenAI's GPT-5.5. GPT-5.5 is one of the strongest models we have...
-
Source: aisi.gov.uk
Title: AISI. Home · About us · Grants.Read more
Link: https://www.aisi.gov.uk/category/science-of-evaluationsSource snippet
Science of Evaluations | AISI Work Category5 Mar 2026 — The AI Security Institute is a research organisation within the Department of Sci...
-
Source: aisi.gov.uk
Title: aisi frontier ai trends report 2025
Link: https://www.aisi.gov.uk/research/aisi-frontier-ai-trends-report-2025Source snippet
AISI Frontier AI Trends Report (2025)18 Dec 2025 — The UK AI Security Institute (AISI) has conducted evaluations of frontier AI systems s...
-
Source: aisi.gov.uk
Title: our 2025 year in review
Link: https://www.aisi.gov.uk/blog/our-2025-year-in-reviewSource snippet
AISI Work22 Dec 2025 — Our 2025 year in review. Adam Beaumont, Director of the UK AI Security Institute, reflects on the year's biggest a...
-
Source: aisi.gov.uk
Link: https://www.aisi.gov.uk/Source snippet
nced AI and to develop and test risk mitigations.Read more...
-
Source: aisi.gov.uk
Title: inspect [evals]({{ ‘evals/’ | relative_url }})
Link: https://www.aisi.gov.uk/blog/inspect-evalsSource snippet
Announcing Inspect Evals | AISI Work13 Nov 2024 — Inspect Evals are built on top of Inspect AI, an open-source evaluation framework creat...
-
Source: OpenAI
Link: https://openai.com/Source snippet
comOpenAI | Research & DeploymentWe believe our research will eventually lead to artificial general intelligence, a system that can solve...
-
Source: OpenAI
Link: https://openai.com/careers/researcher-frontier-cybersecurity-risks-san-francisco/Source snippet
comResearcher, Frontier Cybersecurity RisksPreparedness is a critical Safety Research team at OpenAI, which is focused on mitigating AI...
-
Source: OpenAI
Link: https://openai.com/careers/model-policy-frontier-cyber-risk-san-francisco/Source snippet
comModel Policy, Frontier Cyber RiskIn this role, you will help define how OpenAI's models should behave in high-risk cybersecurity conte...
-
Source: anthropic.com
Title: responsible scaling policy v3
Link: https://www.anthropic.com/news/responsible-scaling-policy-v3Source snippet
Responsible Scaling Policy Version 3.0Feb 24, 2026 — We're releasing the third version of our Responsible Scaling Policy (RSP), the volun...
-
Source: anthropic.com
Link: https://www.anthropic.com/responsible-scaling-policySource snippet
Anthropic's Responsible Scaling PolicyThis setup will be designed to be adapted and updated easily to respond to new threats by adding ne...
-
Source: GOV.UK
Title: ai security institute frontier ai trends report factsheet
Link: https://www.gov.uk/government/publications/ai-security-institute-frontier-ai-trends-report-factsheetSource snippet
Security Institute – Frontier AI Trends report factsheet18 Dec 2025 — The UK AI Security Institute (AISI) has conducted evaluations of...
-
Source: governance.ai
Link: https://www.governance.ai/analysis/anthropics-rsp-v3-0-how-it-works-whats-changed-and-some-reflectionsSource snippet
Anthropic's RSP v3.0: How it Works, What's Changed, and...17 Mar 2026 — The RSP describes how Anthropic intends to assess and mitigate p...
-
Source: arxiv.org
Link: https://arxiv.org/pdf/2509.24394Source snippet
a. It requests systematic evaluations of AI capabilities for...R...
-
Source: ncsc.gov.uk
Title: why cyber defenders need to be ready for frontier ai
Link: https://www.ncsc.gov.uk/blogs/why-cyber-defenders-need-to-be-ready-for-frontier-aiSource snippet
30 Mar 2026 — Since frontier AI capabilities potentially strengthen cyber attackers, cyber defenders must use the same capabilities to dr...
-
Source: fas.org
Title: scaling ai safety
Link: https://fas.org/publication/scaling-ai-safety/Source snippet
“What risks are covered?”.Read more...
-
Source: ratings.safer-ai.org
Link: https://ratings.safer-ai.org/company/openai/Source snippet
– Risk Management Ratings - SaferAI“Within our wider safety stack, our Preparedness Framework is specifically focused on frontier AI risk...
-
Source: iaps.ai
Title: responsible scaling
Link: https://www.iaps.ai/research/responsible-scalingSource snippet
Comparing Government Guidance...11 Mar 2024 — “Responsible capability scaling” is the specification of progressively higher levels of ri...
-
Source: ukauthority.com
Link: https://www.ukauthority.com/articles/ai-security-institute-highlights-progress-in-cyber-securitySource snippet
AI Security Institute highlights progress in cyber security18 Dec 2025 — For the first time, a model has completed an expert level cyber...
-
Source: regulations.ai
Title: RAI GB NA ASIRRXX 2025
Link: https://regulations.ai/regulations/RAI-GB-NA-ASIRRXX-2025Source snippet
AI Security Institute (renaming / rebrand of AI Safety Institute)6 Jan 2026 — In February 2025 the UK government announced that the AI Sa...
Published: February 2025
-
Source: aigl.blog
Link: https://www.aigl.blog/ai-security-institute-frontier-ai-trends-report-december-2025/Source snippet
AI Security Institute – Frontier AI Trends Report (December...Models now reliably complete apprentice-level tasks and have begun to succ...
Additional References
-
Source: scribd.com
Link: https://www.scribd.com/document/866229201/Anthropic-s-Responsible-Scaling-Policy-version-2-2Source snippet
Anthropic Responsible Scaling Policy 2.2 | PDF | SecurityThe Responsible Scaling Policy (RSP) outlines Anthropic's commitment to safely t...
-
Source: verifywise.ai
Link: https://verifywise.ai/ai-governance-library/policies-and-internal-governance/anthropic-responsible-scaling-policySource snippet
Anthropic Responsible Scaling PolicyAnthropic's Responsible Scaling Policy defines AI Safety Levels (ASL) based on model capabilities and...
-
Source: metr.org
Link: https://metr.org/assets/common-elements-nov-2024.pdfSource snippet
Common Elements of Frontier AI Safety PoliciesAnthropic's Responsible Scaling Policy, page 4: Cyber Operations: The ability to significan...
-
Source: futureoflife.org
Link: https://futureoflife.org/wp-content/uploads/2025/11/Indicator-Risk_Identification.pdfSource snippet
EU AI Code of Practice Safety and...The Framework identifies threat modeling as "a causal pathway for a severe harm in the capability ar...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/medium-risk-ai-facilitating-biological-threats-gianluca-mondillo-md-5gxdfSource snippet
Medium Risk of AI in Facilitating Biological ThreatsThe Preparedness Framework developed by OpenAI was designed to ensure that advanced a...
-
Source: linkedin.com
Link: https://www.linkedin.com/pulse/openais-preparedness-framework-scaling-ai-responsibly-cyril-bhr4eSource snippet
OPENAI'S PREPAREDNESS FRAMEWORK: SCALING...The framework is designed to track and prepare for risks associated with “frontier capabiliti...
-
Source: reuters.com
Link: https://www.reuters.com/business/openai-warns-new-models-pose-high-cybersecurity-risk-2025-12-10/Source snippet
According to a blog post, future AI capabilities might be leveraged to create zero-day remote exploits or assist in complex cyber intrusi...
-
Source: linkedin.com
Link: https://www.linkedin.com/posts/openai_strengthening-cyber-resilience-as-ai-capabilities-activity-7404612226835415040-ZmN2Source snippet
Strengthening Cybersecurity Safeguards with Global ExpertsModel capabilities are advancing fast and we expect OpenAI's upcoming models to...
-
Source: inspect.aisi.org.uk
Link: https://inspect.aisi.org.uk/Source snippet
AIInspect can be used for a broad range of evaluations that measure coding, agentic tasks, reasoning, knowledge, behavior, and multi-moda...
-
Source: ddg.fr
Link: https://www.ddg.fr/actualite/frontier-artificial-intelligence-what-the-uk-ai-security-institute-2025-report-reveals-about-risk-safety-and-legal-responsibilitySource snippet
Frontier AI: Risks, Safety and Legal Accountability15 Jan 2026 — In 2025, the Institute tested the first model able to perform expert-lev...
Topic Tree